
محاسبات ترکیبی: مزایای حافظه مشترک و توزیع شده ترکیبی
قبلاً در این مجموعه وبلاگ ، همکار من Pär شبیهسازیهای عددی موازی با COMSOL Multiphysics بر روی پلتفرمهای حافظه مشترک و توزیعشده را توضیح داد. امروز ترکیب این دو روش را مورد بحث قرار می دهیم: محاسبات ترکیبی . من سعی خواهم کرد جنبه های مختلف محاسبات و مدل سازی هیبریدی را روشن کنم و نشان دهم که چگونه COMSOL Multiphysics می تواند از تنظیمات ترکیبی استفاده کند تا بهترین عملکرد را در سیستم عامل های موازی به نمایش بگذارد.
معرفی محاسبات ترکیبی
در سالهای اخیر، سیستمهای خوشهای با استفاده از جدیدترین فناوریهای چند هستهای قدرتمندتر شدهاند. موازی سازی اکنون در چندین سطح گسترش یافته است. سیستمهای عظیم باید با موازیسازی گرهها، سوکتها، هستهها و حتی واحدهای برداری (که در آن عملیات بر روی بردارهای کوتاه یا آرایههای 1 بعدی دادهها انجام میشود، نه بر روی مقادیر اسکالر یا آیتمهای دادهای منفرد) مقابله کنند.
علاوه بر این، سیستم های حافظه در چندین سطح نیز سازماندهی شده اند. و همانطور که این سلسله مراتب عمیق تر و عمیق تر و پیچیده تر می شوند، مدل های برنامه نویسی و اجرا باید این تنظیمات تودرتو را منعکس کنند. به نظر می رسد که پرداختن به یک مدل برنامه نویسی و اجرا کافی نیست . بنابراین، محاسبات به طور فزاینده ای ترکیبی می شود .
قانون هسته و خوشه ها
چندین هسته محاسباتی در همه جا وجود دارند و همه باید با موازی سازی مقابله کنند. از آنجایی که فرکانسهای ساعت در سطح بالایی در حدود 2 تا 5 گیگاهرتز متوقف شدهاند، نیاز روزافزون به قدرت محاسباتی تنها با افزودن هستههای بیشتر و بیشتر برطرف میشود. قانون معروف مور به قانون Core نتیجهای تبدیل شده است که بیان میکند که تعداد هستهها در هر منطقه به طور تصاعدی افزایش مییابد.
پیامد مستقیم این توسعه این است که منابع هر هسته (به عنوان مثال حافظه نهان و تعداد کانال های حافظه) به دلیل تدارکات کوچکتر می شود. جدیدترین نمونههای چند هستهای، از نوع کلاسیک CPU، تا شانزده هسته دارند اما تنها تا چهار کانال حافظه دارند.
به طور معمول، چندین CPU چند هستهای، گرههای حافظه مشترک بسیار توانمندی را ارائه میکنند که قدرت محاسباتی چشمگیری را بر حسب GigaFLOP/s (یعنی میلیارد عملیات ممیز شناور در ثانیه ) به ارمغان میآورند. سپس تعدادی از این گرههای حافظه مشترک از طریق اتصالات پرسرعت در خوشهها ادغام میشوند – منابع تقریباً نامحدودی از نظر (Giga/Tera/Peta)FLOP/s و ظرفیتهای حافظه فراهم میکنند. تنها محدودیت ها بودجه و فضای طبقه بخش IT شما است.
این روزها، یک سیستم کلاستر باید بیش از 100000 هسته داشته باشد تا بتواند رتبه بالایی در لیست TOP500 اخیر کسب کند .
رسیدن به محدودیت ها
یک خوشه نشان دهنده یک سیستم حافظه توزیع شده است که در آن پیام ها از طریق ارسال پیام بین گره ها ارسال می شوند. در اینجا، Message Passing Interface (MPI) با چندین پیادهسازی منبع باز و تجاری استاندارد defacto است. به طور معمول، در داخل گره، OpenMP برای برنامه نویسی حافظه مشترک استفاده می شود.
با این حال، آزمایشهای عددی به راحتی محدودیتهای پلتفرمهای چند هستهای را آشکار میکنند: غذا دادن به جانوران روز به روز دشوارتر میشود. به بیان ساده، دریافت آنقدر سریع داده به هستهها سخت است که بتوان آنها را مشغول نگه داشت و اعداد را به هم ریخت. اساساً، میتوان گفت که FLOP/s بهصورت رایگان در دسترس هستند، اما باید به شدت محاسباتی ، یعنی تعداد FLOP در هر عنصر داده – یکی از مشخصههای الگوریتم، توجه داشته باشید. شدت محاسباتی یک حد بالایی برای نرخ FLOP/s قابل دستیابی است.
اگر شدت محاسبات به صورت خطی در اندازه مسئله افزایش یابد، پهنای باند عملکرد را محدود نمی کند. اما عملیات معمولی برای شبیهسازی عددی اجزای محدود از نوع ماتریس-بردار پراکنده است که محدود به پهنای باند است و پهنای باند معمولاً متناسب با تعداد کانالهای حافظه در یک سیستم چند هستهای است. هنگامی که پهنای باند حافظه موجود اشباع شد، روشن کردن هسته های بیشتر و بیشتر ارزش افزوده ای ندارد. به همین دلیل است که افزایش سرعت در پردازندههای چند هستهای و پلتفرمهای حافظه مشترک اغلب اشباع میشود، زیرا ترافیک حافظه در حال حاضر در حداکثر سطح است، حتی اگر همه هستهها برای محاسبات استفاده نمیشوند. از سوی دیگر، سیستمهای خوشهای از مزایای اضافی افزایش پهنای باند انباشته شده و در نتیجه عملکرد بهتر برخوردار هستند.اینجا .)
در بخش سختافزار، تلاشهایی برای کاهش محدودیتهای پهنای باند با معرفی سلسله مراتبی از کشها انجام شده است . این حافظهها میتوانند از کشهای سطح ۱ کوچک، محدود به یک هسته با تنها چند صد کیلوبایت حافظه، تا کشهای سطح ۳ بزرگ، که بین چندین هسته مشترک با حداکثر چند ده مگابایت حافظه به اشتراک گذاشته میشوند، متغیر باشند. هدف از حافظه پنهان نگه داشتن داده ها تا حد امکان به هسته ها است، به طوری که داده هایی که قرار است دوباره استفاده شوند نیازی به انتقال مکرر از حافظه اصلی نداشته باشند. این کار مقداری از فشار را از کانال های حافظه حذف می کند.
حتی یک پردازنده چند هسته ای به تنهایی می تواند سلسله مراتب حافظه تودرتو ایجاد کند. با این حال، بستهبندی چندین پردازنده چند هستهای در چندین سوکت، یک گره حافظه مشترک با دسترسی غیریکنواخت حافظه (NUMA) ایجاد میکند. به عبارت دیگر، بخشی از داده های برنامه در حافظه محلی به یک هسته و برخی از داده ها در مکان های حافظه دور ذخیره می شود. بنابراین، برخی از بخشهای داده را میتوان بسیار سریع در دسترس قرار داد در حالی که دسترسیهای دیگر دارای تأخیر طولانیتری هستند. این بدان معنی است که قرار دادن صحیح داده ها و توزیع متناظر وظایف محاسباتی برای عملکرد بسیار مهم است.
آگاهی از سلسله مراتب در عملکرد
ما آموختهایم که سیستمهای حافظه مشترک یک سیستم سلسله مراتبی از هستهها و حافظهها ایجاد میکنند و مدل برنامهنویسی، الگوریتمها و پیادهسازیها باید کاملاً از این سلسله مراتب آگاه باشند. از آنجایی که منابع محاسباتی یک گره حافظه مشترک محدود است، می توان با اتصال چندین گره حافظه مشترک توسط یک شبکه اتصال سریع در محاسبات توزیع شده، توان اضافی اضافه کرد.
برای بازگرداندن قیاس قبلی خود از پست های وبلاگ حافظه مشترک و محاسبات حافظه توزیع شده ، اکنون از تعداد متغیری از مکان های کنفرانس برای نمایش خوشه استفاده می کنیم، جایی که هر مکان یک اتاق کنفرانس با یک میز بزرگ برای نشان دادن یک گره حافظه مشترک فراهم می کند.
اگر کار کلی که باید انجام شود بیشتر و بیشتر شود، مدیر کنفرانس می تواند برای کمک با سایر مکان های شرکت تماس بگیرد. فرض کنید اتاق های کنفرانس در بوستون، سانفرانسیسکو، لندن، پاریس و مونیخ قرار دارند. این مکان های دور نشان دهنده فرآیندهای حافظه توزیع شده (فرایندهای MPI) هستند. مدیر اکنون میتواند مکانهای جدیدی را در صورت تقاضا، مانند افزودن استکهلم، اضافه کند — یا از نظر محاسبات ترکیبی، میتواند فرآیندهای اضافی (یعنی میزهای کنفرانس) را در هر گره حافظه مشترک (یعنی در هر مکان اتاق کنفرانس) تنظیم کند.
هر مکان اتاق کنفرانس ( فرآیند ) یک تلفن روی میز در اتاق جلسه دارد که کارمندان می توانند از آن برای تماس با هر مکان دیگر ( فرایند دیگر ) و درخواست داده یا اطلاعات ( ارسال پیام ) استفاده کنند. کارکنان محلی (یک منبع محدود) دور هر میز کنفرانس در یک مکان خاص نشسته اند. هر کارمند در میز کنفرانس نشان دهنده یک رشته است که به حل وظایف در میز اتاق کنفرانس کمک می کند.
روی جدول، دادههای محلی در یک گزارش ( حافظههای پنهان سطح 1 )، در پوشهها ( حافظههای پنهان سطح 2 )، در پوشههای واقع در داخل کابینتها ( حافظههای سطح 3 )، در کتابخانه در همان طبقه ( حافظه اصلی ) در دسترس هستند. ، یا در بایگانی در زیرزمین ( هارد دیسک ) بایگانی می شوند. چندین دستیار ( کانال های حافظه ) در ساختمان در حال اجرا هستند تا پوشه های جدید را با اطلاعات درخواستی از کتابخانه یا آرشیو دریافت کنند. تعداد دستیارها محدود است و آنها فقط می توانند تعداد محدودی پوشه را به طور همزمان حمل کنند ( پهنای باند ).
اگر دستیاران بیشتری در دسترس نباشند که بتوانند داده های کافی برای کار با آنها بیاورند، داشتن افراد بیشتر روی میز هیچ ارزشی اضافه نمی کند. واضح است که مدیر کنفرانس باید اطمینان حاصل کند که دادههای لازم برای کار روی میز موجود است و همه کارمندان در اتاق میتوانند به طور مؤثر برای دستیابی به راهحلی برای یک مشکل معین کمک کنند. او همچنین باید مطمئن شود که تعداد تماسها با سایر مکانهای کنفرانس از طریق تلفن روی میز به حداقل برسد. از نظر عددی، پیادهسازیها باید از سلسله مراتب آگاه باشند، دادهها باید محلی نگه داشته شوند و میزان ارتباطات باید به حداقل برسد.
تماس های تلفنی بین مکان های کنفرانس نشان دهنده تماس های MPI بین فرآیندها است. روی میز اتاق جلسه، مکانیزم حافظه مشترک باید به کار گرفته شود. در مجموع، تعامل کامل حافظه توزیع شده (MPI) و حافظه مشترک (OpenMP) مورد نیاز است.
نمونه ای از پیکربندی خوشه ترکیبی
بیایید نگاهی دقیق تر به برخی از تنظیمات خوشه و هسته احتمالی بیندازیم. در مدل آزمایشی خود در زیر، ما یک خوشه کوچک را بررسی کردیم که از سه گره حافظه مشترک تشکیل شده است. هر گره دارای دو سوکت با یک پردازنده چهار هسته ای در هر سوکت است. تعداد کل هسته ها 24 است. هر پردازنده دارای یک بانک حافظه محلی است که پیکربندی NUMA حافظه اصلی را نیز نشان می دهد.
حال، مواردی را آزمایش میکنیم که در آن سه، شش، دوازده یا بیست و چهار فرآیند MPI روی این خوشه پیکربندی شدهاند. با سه فرآیند MPI، ما یک پردازش MPI در هر گره و هشت رشته در هر فرآیند MPI داریم که می تواند از طریق حافظه مشترک/OpenMP در داخل گره و در دو سوکت گره ارتباط برقرار کند. با شش پردازش MPI ما یک پردازش MPI در هر سوکت خواهیم داشت، یعنی یک پردازش برای هر پردازنده. سپس هر فرآیند MPI به چهار رشته نیاز دارد. سومین امکان از دوازده فرآیند MPI، راه اندازی دو پردازش MPI در هر پردازنده با دو رشته است. در نهایت، میتوانیم یک فرآیند MPI را در هر هسته آزمایش کنیم که مجموعاً به بیست و چهار فرآیند MPI روی سیستم میرسد. این حالت غیر ترکیبی است، که در آن به موازی سازی حافظه مشترک نیاز نیست و تمام ارتباطات از طریق حافظه توزیع شده انجام می شود.
به نظر شما کدام پیکربندی بهترین است؟
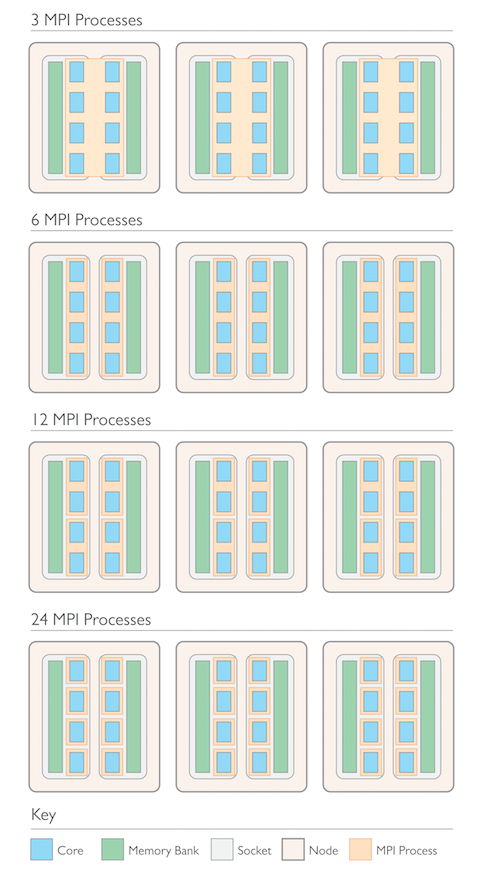
پیکربندی های مختلف MPI در یک خوشه با سه گره حافظه مشترک متشکل از دو سوکت، هر کدام با یک پردازنده چهار هسته ای و بانک های حافظه محلی.
چرا هیبرید؟
چرا از یک مدل برنامه نویسی و اجرا استفاده نمی کنیم و هسته سلسله مراتبی و پیکربندی حافظه را نادیده می گیریم؟ اول از همه، به این دلیل است که مکانیسمهای حافظه مشترک (OpenMP) نمیتوانند به صورت جهانی در سیستمهای نوع استاندارد با نصب استاندارد استفاده شوند (هیچ جدول جهانی برای اشتراکگذاری دادهها موجود نیست).
پس چرا از انتقال پیام به صورت سراسری در تمام هستهها استفاده نمیکنید – با 24 فرآیند MPI مانند مثال بالا؟ البته ممکن است؛ شما می توانید از ارسال پیام حتی بین هسته ها در همان گره حافظه مشترک استفاده کنید. اما به این معنی است که هر کارمند، در قیاس ما در بالا، تلفن خود را دارد و باید با همه کارمندان دیگر در سراسر جهان تماس بگیرد. ممکن است مشکلات سیگنالهای درگیر یا افراد در حالت تعلیق و در نتیجه کار نکردن وجود داشته باشد.
در واقع، سناریوی واقعی پیچیدهتر است، زیرا پیادهسازیهای MPI مدرن به خوبی از سلسلهمراتب آگاه هستند و برای استفاده از مکانیسمهای حافظه مشترک برای ارتباطات محلی کوتاه شدهاند. یکی از نقاط ضعف MPI این است که منابع حافظه به صورت درجه دوم در تعداد فرآیندهای شرکت کننده هدر می رود. دلیل این امر این است که بافرهای داخلی در جایی که داده ها ذخیره می شوند (و احتمالاً تکراری) قبل از ارسال پیام های واقعی بین فرآیندها تنظیم می شوند. در 10 6 هسته، این به 10 12 بافر حافظه برای یک تماس ارتباطی جهانی نیاز دارد (اگر اجرای MPI از سلسله مراتب آگاه نباشد). در محاسبات ترکیبی، تعداد فرآیندهای MPI معمولاً کمتر از تعداد هسته است – باعث صرفه جویی در منابع از نظر حافظه و انتقال داده می شود.
یکی دیگر از مزایای بزرگ استفاده از مدل ترکیبی این است که بسیاری از مکانیسم ها (مانند قرار دادن داده ها، پین کردن نخ، یا متعادل کردن بار، به نام چند) به برخی اقدامات اختصاصی برنامه نویس نیاز دارند. مدل ترکیبی ابزار بسیار متنوع تری برای بیان این جزئیات فراهم می کند. مزایای یک دید کلی و گسسته از حافظه را به اشتراک می گذارد. در نظر گرفتن مدل هیبریدی OpenMP + MPI یک انتخاب طبیعی است زیرا با ساختار ترکیبی حافظه و پیکربندی هسته مطابقت دارد، همانطور که در شکل ها نشان داده شده است.
مهمتر از همه، مدل هیبریدی انعطاف پذیر و سازگار است و به کاهش هزینه های سربار و تقاضا برای منابع کمک می کند. از نظر مدل سازی اجزای محدود، سلسله مراتب در داده ها و وظایف اغلب می تواند از مدل فیزیکی، هندسه آن، الگوریتم ها و حل کننده های مورد استفاده استخراج شود. سپس این سلسله مراتب را می توان به مکانیسم های حافظه مشترک و توزیع شده ترجمه کرد.
البته، مدل ترکیبی همچنین مشکلات حافظه مشترک و محاسبات توزیع شده را ترکیب می کند و در نهایت بسیار پیچیده تر می شود. با این حال، نتیجه نهایی ارزش تلاش را دارد! COMSOL Multiphysics ساختارهای داده و الگوریتم های پیچیده ای را ارائه می دهد که موازی سازی چند سطحی را تا حد زیادی نشان می دهد و از آن بهره برداری می کند. از حافظه مشترک و حافظه توزیع شده به طور همزمان پشتیبانی می کند و کاربر می تواند تعامل هر دو را با مجموعه ای از پارامترها برای بهترین عملکرد تنظیم کند.
محک زدن مدل ها و سیستم شما
پس از تمام این توضیحات تئوریک، اکنون زمان آن رسیده است که این مفهوم را با مدل های واقعی مرتبط کنیم. من تصور می کنم که شما کاملاً کنجکاو هستید که مقیاس پذیری، افزایش سرعت و بهره وری را هنگام اجرای موازی COMSOL Multiphysics روی سرورها و خوشه های محاسباتی در بخش خود بررسی کنید.
برای به دست آوردن نتایج مناسب، توجه به اندازه مشکل بسیار مهم است. اندازه مشکلات فرعی در یک گره حافظه مشترک باید به اندازه کافی بزرگ باشد تا هر رشته بتواند مقدار معقولی کار را به دست آورد و نسبت محاسبات در هر فرآیند به مقدار داده رد و بدل شده از طریق پیام بین فرآیندها به اندازه کافی بزرگ باشد. همانطور که Pär در پست قبلی وبلاگ خود ذکر کرده بود ، بسیار مهم است که در نظر بگیریم که آیا مشکلات اصلاً قابل موازی هستند یا خیر. به عنوان مثال، اگر تلاش اصلی هنگام تنظیم مدل شما به محاسبه یک سری گامهای زمانی طولانی (که ممکن است برای ساعتها طول بکشد) اختصاص داده شود، اما اندازه مشکل در هر مرحله زمانی بهطور قابلتوجهی بزرگ نباشد، هنگام افزایش سرعت، مزایای قابل توجهی نخواهید دید. تا گره ها و هسته های اضافی.
من شما را تشویق می کنم که پیکربندی های مختلف مدل هیبریدی را امتحان کنید، حتی زمانی که فقط یک دستگاه حافظه مشترک در دسترس دارید.
مطالعه مقیاس پذیری ترکیبی
در سناریوی آزمایشی ارائه شده در اینجا، ما یک مدل مکانیک سازه را در نظر می گیریم که نشان دهنده یک رینگ چرخ ده پره است که در آن فشار تایر و توزیع بار شبیه سازی شده است.

مدل رینگ چرخ و مدل فرعی مربوط به آن.
شبیه سازی ما بر روی سه گره محاسباتی ذکر شده در بالا اجرا می شود، جایی که هر گره دارای دو سوکت با یک پردازنده چهار هسته ای Intel Xeon® E5-2609 با 64 گیگابایت رم در هر گره است، و در آن 32 گیگابایت با یک پردازنده مرتبط است. گره ها با اتصال اترنت گیگابیتی (نسبتاً کند) به هم متصل می شوند. در مجموع، ما 24 هسته در این دستگاه خاص داریم.
در نمودار زیر، تعداد شبیهسازیهای این یک مدل را که میتوان در روز اجرا کرد، با توجه به پیکربندی مدل هیبریدی مقایسه میکنیم. ما مورد پردازش های 1، 2، 3، 6، 12 و 24 MPI در حال اجرا را در نظر می گیریم. این منجر به 1، 2، 3، 4، 6، 8، 12، 16 و 24 هسته فعال بسته به پیکربندی می شود. هر نوار در نمودار یک پیکربندی ( nn x np ) را نشان میدهد که nn تعداد پردازشها، np تعداد رشتهها در هر فرآیند و nn*np تعداد هستههای فعال است. میلهها به بلوکهایی با همان تعداد هسته فعال گروهبندی میشوند، جایی که پیکربندی آنها در بالای میلهها فهرست شده است.
نمودار نشان می دهد که عملکرد به طور کلی با تعداد هسته های فعال افزایش می یابد. ما تغییرات جزئی را برای پیکربندی های مختلف می بینیم. هنگام رسیدن به بار کامل سیستم با 24 هسته فعال، متوجه می شویم که بهترین پیکربندی اختصاص دادن یک پردازش MPI برای هر سوکت است (یعنی در مجموع شش پردازش MPI). افزایش عملکرد و بهره وری در سیستم سه گره با پیکربندی فرآیند-رشته ترکیبی (مورد 6×4) بیش از دو برابر عملکرد یک گره حافظه مشترک (مورد 1×8) است. همچنین تقریباً 30 درصد بهتر از مدل کاملاً توزیع شده (مورد 24×1) است که از همان تعداد هسته استفاده می کند.
وقتی این را با پیکربندی کاملاً توزیع شده همسایه آن مقایسه می کنیم (مورد 12×1)، می بینیم که با وجود دو برابر شدن تعداد هسته ها، هیچ سود واقعی در عملکرد وجود ندارد. این به این دلیل است که شبکه اترنت کند گیگابیتی در حال حاضر با 12 فرآیند MPI به محدودیت های خود نزدیک شده است. بنابراین فرآیندهای MPI بیشتر سودمند نیستند. وضعیت در مقایسه پیکربندیهای 12×1 و 12×2 متفاوت است، جایی که تعداد رشتهها در هر فرآیند به همراه تعداد هستههای فعال دو برابر میشود. این اساساً به این معنی است که در این حالت میزان ارتباط از طریق اترنت افزایش نمی یابد.
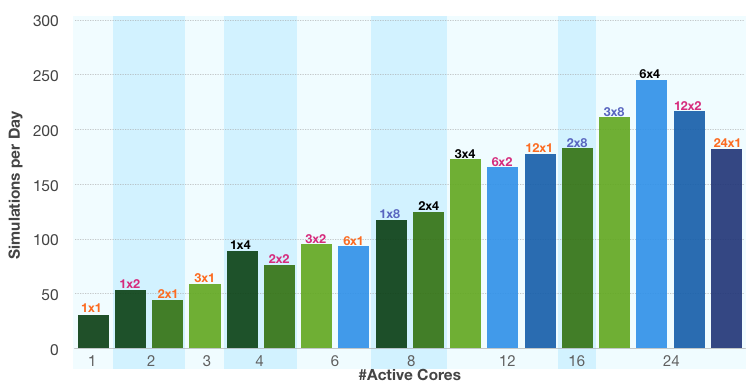
مقایسه یک مدل مکانیک ساختاری یک رینگ چرخ با استفاده از پیکربندیهای مختلف در یک مدل هیبریدی محور y نشان دهنده عملکرد و افزایش بهره وری از طریق تعداد کل شبیه سازی های این مدل است که می تواند در طول یک روز اجرا شود. میلهها پیکربندیهای مختلف nn x np را نشان میدهند که nn تعداد پردازشهای MPI و np تعداد رشتهها در هر فرآیند است.
راه اندازی Hybrid Runs در COMSOL Multiphysics
هنگام اجرای COMSOL Multiphysics در حالت ترکیبی موازی، شما امکانات مختلفی برای تنظیم تعداد فرآیندها و رشته های استفاده شده دارید. برخی از تنظیمات را می توان در بخش Multicore and Cluster Computing در گفتگوی Preference یا در زیرگره Cluster Computing گره Study در Model Builder پیدا کرد. میتوانید تنظیمات را در زیرگره Cluster Computing گره Job Configurations تنظیم کنید ، جایی که میتوانید تعداد گرههای (فیزیکی) را که میخواهید در محاسبات خوشهای خود استفاده کنید، مشخص کنید. با استفاده از منوی کشویی در تنظیماتدر پنجره، شما انتخابهای اضافی دارید، مانند تعداد پردازشها در هر میزبان یا دانهبندی گره، که تصمیم میگیرد که آیا یک فرآیند در هر گره، سوکت یا هسته قرار دهید.
تعداد نخ های استفاده شده در هر فرآیند به طور خودکار تنظیم می شود. COMSOL Multiphysics همیشه از حداکثر تعداد هستههای موجود استفاده میکند، یعنی تعداد هستهها در هر فرآیند به تعداد هستههای موجود روی گره تقسیم بر تعداد پردازشهای روی گره تنظیم میشود. میتوانید با تنظیم تعداد پردازندهها در بخش Multicore در گفتگوی Preferences روی مقدار درخواستی، تعداد هستههای هر فرآیند را لغو کنید.
در سیستمهای لینوکس، گزینههای خط فرمان -nn برای تعداد پردازشها، -np برای بازنویسی تعداد نخهای تعیین شده بهطور خودکار در هر فرآیند، و گزینه -nnhost که تعداد پردازشها را در هر میزبان تنظیم میکند، دارید . یک انتخاب طبیعی برای nnhost یا 1 یا تعداد سوکت در هر گره است.
مراحل بعدی
- برای گزینههای اضافی، موارد استفاده و مثالها لطفاً به مستندات COMSOL Multiphysics مراجعه کنید.
- آخرین پست ما در این سری وبلاگ مدلسازی ترکیبی در مورد موضوع جاروهای دسته ای خواهد بود.
- لینک دانلود به صورت پارت های 1 گیگابایتی در فایل های ZIP ارائه شده است.
- در صورتی که به هر دلیل موفق به دانلود فایل مورد نظر نشدید به ما اطلاع دهید.
برای مشاهده لینک دانلود لطفا وارد حساب کاربری خود شوید!
وارد شوید
دیدگاهتان را بنویسید