
Application Builder چندین روش داخلی برای خواندن و نوشتن انواع مختلف فایلها ارائه میکند: فایلهای متنی، فایلهای CSV، فایلهای Excel® (نیاز به LiveLink™ برای Excel® ) و فایلهای باینری. این روشهای فایل در جدول «روشهای فایل» در صفحه 101 فهرست شدهاند .
توجه داشته باشید که تکنیکهای مبتنی بر رابط کاربری آسان برای خواندن و نوشتن در فایل در ویرایشگر فرم Application Builder موجود است. توصیه می شود قبل از استفاده از روش های مبتنی بر برنامه نویسی که در این بخش توضیح داده شده است، ابتدا آن تکنیک ها را در نظر بگیرید. برای اطلاعات بیشتر، به کتاب مقدمهای بر برنامهساز و «روشهای دستور GUI» در صفحه 127 مراجعه کنید. در آنجا، همچنین می توانید اطلاعاتی در مورد طرح های فایل مختلف مورد استفاده در Application Builder برای خواندن و نوشتن فایل ها هنگام اجرای برنامه ها در مرورگر وب بیابید.
|
•
|
علاوه بر این، می توانید از روش های سطح پایین موجود در کلاس CsReader برای خواندن فایل های متنی خط به خط یا کاراکتر به کاراکتر استفاده کنید. برای اطلاعات بیشتر به بخش بعدی، «پردازش فایلهای متنی با استفاده از کلاسهای CsReader و CsWriter» در صفحه 182 مراجعه کنید.
اگر مجوز LiveLink™ for Excel® دارید ، روشهای زیر برای خواندن و نوشتن فایلهای Microsoft Excel Workbook در دسترس هستند :
|
•
|
فرض کنید میخواهید با ایجاد برنامهای که دادهها را از یک صفحه گسترده میخواند، تجزیه و تحلیل حرارتی خاصی از برد مدار را خودکار کنید. علاوه بر این فرض کنید که اطلاعات مربوط به اجزای برد مدار توسط یک قالب اختصاصی در یک صفحه گسترده با ستون هایی برای نوع قطعه، اتلاف گرما، مکان ها و اندازه ها ارائه شده است. فرض کنید که چنین فایلی به شکل زیر است:
هر ردیف از صفحه گسترده یک جزء متفاوت را نشان می دهد. ستون اول میتواند شامل یک حرف B یا C باشد که نشان میدهد این جزء میتواند بهعنوان یک بلوک یا یک سیلندر اولیه مدلسازی شود. ستون بعدی کل اتلاف گرما در داخل قطعه (اندازه گیری شده بر حسب وات) است. سه ستون بعدی نشان دهنده مکان جزء در سیستم مختصات دکارتی جهانی (اندازه گیری شده بر حسب میلی متر) است. در نهایت، اگر سطر شامل یک جزء بلوک باشد، سه ستون دیگر وجود دارد که عرض، عمق و ارتفاع بلوک را نشان میدهد. اگر ردیف شامل یک جزء استوانه ای باشد، دو ستون دیگر وجود دارد که به ترتیب حاوی اطلاعات شعاع و ارتفاع هستند.
برای مثال نشان داده شده در بالا، ردیف اول صفحه گسترده نشان دهنده خود برد مدار است که ضخامت آن 1.57 میلی متر و 350 میلی متر در 200 میلی متر است. از مبدأ با 1.57- میلی متر در جهت z منحرف می شود و هیچ گرمایی را دفع نمی کند.
میتوانید دادهها را در صفحهگسترده در یک فایل متنی محدود شده با کاما، که به عنوان فایل CSV نیز شناخته میشود، بنویسید. رابط کاربری اپلیکیشن مورد استفاده برای خواندن داده ها در شکل زیر نشان داده شده است.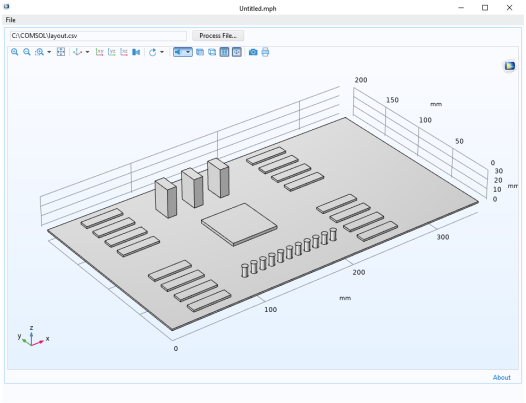

در پنجره تنظیمات ، فایل CSV (*.csv) به لیست انواع فایل اضافه می شود. هنگام مرور فایل، این تنظیم هر فایلی را که یک فایل CSV نیست فیلتر می کند.
همچنین یک File Declaration به نام File 1 وجود دارد که با نحو طرح فایل upload:///inputFile در روش populateBoard ارجاع داده می شود که برای خواندن و پردازش داده ها استفاده می شود. این روش به عنوان رویدادی که در پایین پنجره تنظیمات شی فرم وارد کردن فایل در بخش رویدادها نشان داده شده است فراخوانی می شود .
در خط اول، داده های خوانده شده از فایل CSV در آرایه دو بعدی D ذخیره می شود . بقیه کد این آرایه را تجزیه می کند و قسمت های مختلف یک شی مدل را پر می کند. این برنامه به شما اجازه می دهد تا نتیجه را به عنوان یک فایل MPH با متغیرهای تعریف شده برای منابع گرما و اجسام هندسی تعریف شده برای اجزاء ذخیره کنید، همانطور که در شکل های زیر نشان داده شده است.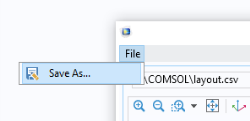
برنامه ای که در بالا توضیح داده شد می تواند به راحتی برای خواندن فایل های Microsoft Excel® Workbook نیز گسترش یابد . توجه داشته باشید که این به LiveLink™ برای Excel ® نیاز دارد . در پنجره تنظیمات برای شیء فرم وارد کردن فایل ، میتوانید مانند شکل زیر Microsoft Excel Workbook (*.xlsx) و Microsoft Excel Workbook (*.xls) را به قسمت File Types اضافه کنید.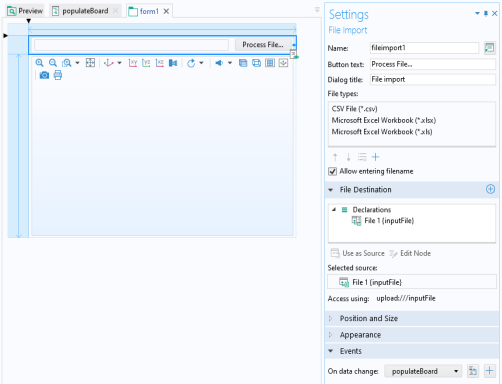
مرحله بعدی اضافه کردن چند خط کد در ابتدای متد populateBoard است، همانطور که در زیر نشان داده شده است.
آرایه دو بعدی D را می توان به عنوان یک آرایه جهانی در گره Declarations در درخت برنامه تعریف کرد. از طرف دیگر، می توان آن را به عنوان یک آرایه که برای متد محلی است، با افزودن خط اعلام کرد
قبل از عبارت if اینکه کدام گزینه را انتخاب کنید بستگی به نحوه استفاده از داده های آرایه دو بعدی پس از خواندن فایل دارد.
متد getFilePath مسیر کامل و نام فایل آپلود شده را برمی گرداند. دستورات if کنترل می کنند که کدام روش برای خواندن فایل بر اساس پسوند فایل آن استفاده می شود. پسوند فایل با متد Java® endsWith() که متعلق به کلاس String است بازیابی می شود. توجه داشته باشید که همانطور که در شکل زیر نشان داده شده است، می توانید با تایپ نام رشته به دنبال نقطه و Ctrl+Space، ببینید کدام روش برای یک رشته در دسترس است.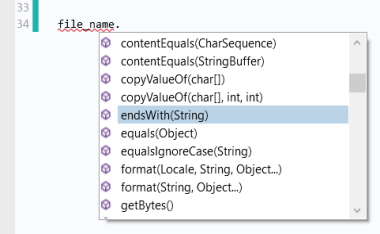
بسته به رشته یا دوتایی بودن محتویات و اینکه میخواهید یک فایل موجود را بازنویسی کنید یا به محتوای آن اضافه شود ، میتوانید با استفاده از چهار نحو فراخوانی مختلف برای روش writeCSVFile روی یک فایل CSV بنویسید.
در مورد بالا، محتویات ترکیبی از اعداد و کاراکترها هستند، بنابراین آرایه دو بعدی که اطلاعات را ذخیره می کند باید یک آرایه رشته ای باشد.
فرض کنید میخواهیم یکی از مؤلفهها، مثلاً دومی را به آخری، در فایل فهرستشده در بالا منتقل کنیم. ما می خواهیم خط مربوطه را در فایل از تغییر دهیم
کد زیر نحوه ایجاد این تغییر و سپس نوشتن داده بر روی این قالب را نشان می دهد، با فرض اینکه آرایه D به عنوان یک متغیر جهانی در گره Declarations ، همانطور که در بالا توضیح داده شد، اعلام شده است.
خط اول اندازه آرایه دو بعدی (یا ماتریس) D را در یک آرایه (یا برداری) 1 در 2 sz ذخیره می کند. خط دوم مقدار رشته مختصات y بلوک ردیف دوم تا آخر در D را تنظیم می کند.
داده ها را در یک فایل my_layout.csv در یک پوشه موقت می نویسد که مکان آن با تنظیمات برگزیده COMSOL Multiphysics یا COMSOL Server، بسته به اینکه کدام نرم افزار برای اجرای برنامه استفاده می شود، تعیین می شود. به عنوان مثال، در یک نصب معمولی Windows® COMSOL Multiphysics، مکان مشابه خواهد بود
توجه داشته باشید که به عنوان اولین مرحله در مثال بالا، فایل با استفاده از روش writeCSVFile در یک فایل موقت نوشته می شود. این مرحله به صورت خودکار توسط اپلیکیشن انجام می شود. در مرحله دوم، روش fileSaveAs یک مرورگر فایل را باز می کند و به کاربر برنامه اجازه می دهد مکان فایل را انتخاب کند. به عنوان مثال، یک پوشه در سیستم فایل محلی رایانه یا یک پوشه شبکه. این مرحله اضافی برای عملکرد برنامه در یک مرورگر وب مورد نیاز است. با توجه به تنظیمات امنیتی یک مرورگر وب معمولی، برنامه مجاز به ذخیره خودکار فایل در یک مکان دلخواه نیست. در عوض، برنامه مجاز است در چند مکان خاص، از جمله پوشه موقت ، که مکان آن در تنظیمات برگزیده مشخص شده است، ذخیره کند.تنظیمات. مکانهای دیگر ، پوشههای کاربر و مشترک هستند که در تنظیمات برگزیده نیز مشخص شدهاند . برای اطلاعات بیشتر، به مقدمه Application Builder مراجعه کنید.
اگر LiveLink™ برای Excel ® مجوز دارید، میتوانید در یک فایل Workbook Microsoft Excel به روشی مشابه فایل CSV بنویسید، با این استثنا که گزینه ضمیمه در دسترس نیست. کد زیر، مطابق با مثال قبلی فایل CSV، نحوه نوشتن در یک فایل اکسل را نشان می دهد.
هنگام استفاده از روش readMatrixFromFile ، خواندن فایلهای دارای دادههای عددی در قالب ماتریس سادهترین کار است. این روش فرض میکند که فایل دارای قالب صفحه گسترده است، همانطور که در گره صادراتی درخت مدل موجود است . مثال زیر فایلی را در قالب صفحه گسترده نشان می دهد.
چند خط اول با کامنت ها با کاراکتر % شروع می شود و با روش readMatrixFromFile نادیده گرفته می شود. شما می توانید به صورت اختیاری چنین خطوطی را حذف کنید و فقط قسمت عددی یک فایل را توسط readMatrixFromFile خوانده شود . فرض کنید که این فایل با استفاده از یک شی فرم وارد کردن فایل و یک file declaration file1 در یک برنامه آپلود شده است . سپس از کد زیر می توان برای خواندن داده ها در یک آرایه دوتایی p استفاده کرد.
کد زیر نحوه وارد کردن و تجسم این نقاط را در برنامهای نشان میدهد که علاوه بر یک شیء فرم Import فایل و یک فایل اعلان فایل ، دارای فرم form1 و شیء گرافیکی graphics1 است.
خواندن فایل ها در قالب صفحه گسترده به عنوان یک آرایه رشته ای می تواند با روش readStringMatrixFromFile انجام شود . همچنین در این صورت خطوط نظرات نادیده گرفته می شود. کد زیر نشان می دهد که چگونه می توانید چند خط اول را در مثال بالا با استفاده از readStringMatrixFromFile به جای readMatrixFromFile جایگزین کنید .
برای نوشتن داده های ماتریس عددی در فایل، می توانید از روش writeFile استفاده کنید . فرض کنید می خواهید ماتریسی از مقادیر مختصات تصادفی دوبعدی را در یک فایل در قالب صفحه گسترده بنویسید. مثلا:
فایل به دست آمده را می توان با استفاده از کد مثال قبلی دوباره خواند و رسم کرد. نتیجه در یک برنامه ممکن است مانند شکل زیر باشد.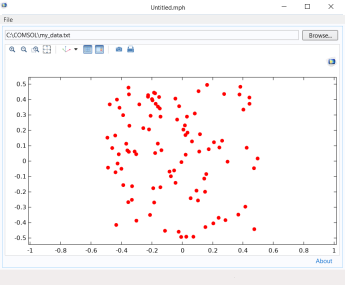
توجه داشته باشید که میتوانید با ارائه یک آرگومان ورودی بولی اضافی، دادهها را به یک فایل موجود اضافه کنید. مثلا:
اگر میخواهید ماتریسی را با ترکیبی از دادههای عددی و متنی صادر کنید، میتوانید از متد writeFile با آرایه رشتهای به جای آرایه دوگانه استفاده کنید. نحو برای این مورد در غیر این صورت با آرایه دوگانه نشان داده شده در مثال بالا یکسان است.
برای خواندن فایل های متنی در یک رشته، می توانید از روش readFile استفاده کنید . استفاده ساده از readFile برای پیش نمایش یک فایل متنی است. برای مثال، قبل از وارد کردن و تجزیه آن، همانطور که در برنامه مثال در شکل زیر نشان داده شده است.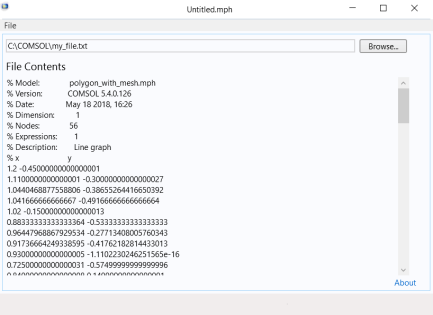
این برنامه دارای دو شیء فرم است: یک شیء فرم Import که به یک فایل اعلان فایل ارجاع میدهد و یک شیء فرم متنی که به یک رشته str اعلام شده در گره Declarations به عنوان یک متغیر سراسری ارجاع میدهد.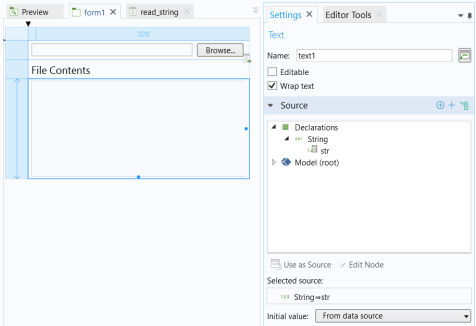
از آنجایی که شی Text به رشته سراسری str ارجاع می دهد ، محتویات فایل بلافاصله پس از وارد کردن در شی Text نمایش داده می شود.
تجزیه فایل های متنی کوچکتر را می توان با readFile در ترکیب با بسیاری از روش های پردازش متن موجود در کلاس String انجام داد. با این حال، استفاده از روشها در کلاس CsReader اغلب کارآمدتر است، همانطور که در بخش «پردازش فایلهای متنی با استفاده از کلاسهای CsReader و CsWriter» در صفحه 182 ، بهویژه برای فایلهای متنی بزرگتر توضیح داده شده است. دلیل آن این است که هنگام استفاده از روش readFile ، کل فایل به صورت رشته ای خوانده می شود که تمام محتویات آن در حافظه نگهداری می شود. در حالی که هنگام استفاده از متدهای کلاس CsReader ، تنها بخش های کوچکی از فایل در هر زمان معین در حافظه نگهداری می شود.
اگر میخواهید فایلهای متنی کوچکتر را با استفاده از readFile تجزیه کنید ، «روشهای رشتهای» داخلی در صفحه 150 مفید هستند. کد مثال زیر استفاده از روشهای داخلی findIn ، substring ، split و همچنین روشهای معمولی Java® System.getProperty و String.startsWith را نشان میدهد . مثال، هدر یک فایل متنی حاوی اطلاعات چند ضلعی را برای بازیابی اطلاعات در مورد تعداد نقاط هر چند ضلعی در بدنه اصلی فایل (نشان داده نشده) و همچنین تعداد ویژگی ها (مثلاً ویژگی رنگ یا ماده) تجزیه می کند. . قسمت هدر فایل ممکن است مانند مثال زیر باشد.
Demo file for string parsing
Created on May 1st 2018
begin_header
number_of_points 4
number_of_properties 4
end_header
کد تجزیه هدر در زیر لیست شده است. تعداد نقاط و خصوصیات را به ترتیب در متغیرهای n_of_points و n_of_properties ذخیره می کند. برای ساده نگه داشتن کارها، رسیدگی به خطا انجام نمی شود. برای مثال، کد فرض میکند که دقیقاً یک نمونه از begin_header و end_header وجود دارد.
String headerContents = substring(fileContents, headerBeginIndex, headerEndIndex-headerBeginIndex); // Convert to string array by splitting at each line.
کلاس Java® String متدهای زیادی برای پردازش متن دارد. برای اطلاعات بیشتر به مستندات آنلاین Java® مراجعه کنید.
استفاده از طرح فایل temp:/// در مثال های قبلی این بخش در بالا توضیح داده شده است. کاراکترهای انتهای خط این مثال برای Windows® هستند. همچنین به “شخصیت های خاص” در صفحه 11 مراجعه کنید.
کارآمدترین و منعطف ترین روش برای خواندن و نوشتن در یک فایل متنی استفاده از متدهای کلاس CsReader و CsWriter است. با این حال، استفاده از روشهای این کلاسها پیچیدهتر از استفاده از هر یک از روشهای داخلی توصیفشده در بالا است.
کلاس CsReader تمام متدهای عمومی کلاس انتزاعی Java® Reader را به ارث می برد . به روشی مشابه، کلاس CsWriter تمام متدهای عمومی کلاس انتزاعی Java® Writer را به ارث می برد . این بدان معناست که هنگام استفاده از این کلاس ها، به تعداد زیادی روش برای پردازش فایل های متنی دسترسی دارید. این روشها در اینجا مستند نشدهاند، اما میتوانید اطلاعات زیادی در رابطه با استفاده از این روشها به صورت آنلاین و همچنین در کتابهای برنامهنویسی جاوا پیدا کنید. علاوه بر این، با استفاده از Ctrl+Space میتوانید ببینید کدام روشها در دسترس هستند.
کد مثال زیر نحوه تجزیه هدر فایل متنی مثال قبلی را برای خواندن رشته ها با استفاده از روش داخلی readFile نشان می دهد. هدر ممکن است به این صورت باشد:
while (begin_header_found && !end_header_found && li < max_header_length && ((line = reader.readLine()) != null)) {
که خواندن یک خط از جریان کاراکتر و ذخیره نتیجه در خط رشته است . در نظر گرفته میشود که یک خط با یکی از نویسههای بازگشت \r ، تغذیه خط \n یا ترکیب \r\n خاتمه یافته است. اگر خط دیگری برای خواندن وجود نداشته باشد، null برگردانده می شود.
برای اطلاعات بیشتر در مورد روشهای رشتهای که در این و نمونههای قبلی استفاده میشود، از جمله findIn ، substring و split ، به بخش «نوشتن رشته در یک فایل متنی» در صفحه 181 مراجعه کنید.
توجه داشته باشید که همانطور که در شکل زیر نشان داده شده است، می توانید با استفاده از Ctrl+Space ببینید کدام روش های اضافی برای شی Reader در دسترس هستند.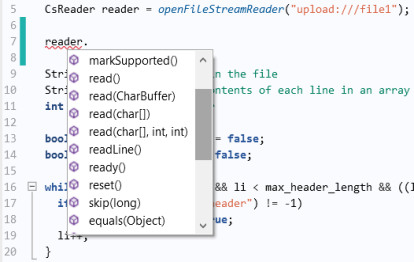
با استفاده از Ctrl+Space به دنبال یک رشته، میتوانید بسیاری از روشهای اضافی موجود برای رشتهها، از جمله روش trim مورد استفاده در مثال بالا را ببینید: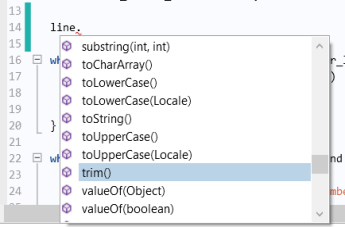
مثال بخش “خواندن فایل های ماتریس” در صفحه 177 از نمونه ای در قالب داده صفحه گسترده استفاده می کند. این بخش شامل مثالی است که فایلی را با فرمت Sectionwise می نویسد، فرمت اصلی دیگر در COMSOL Multiphysics برای ذخیره داده های پس از پردازش. برای مثال، دادههای قالب مقطعی را میتوان در یک هندسه اولیه منحنی درونیابی خواند. یک فایل با فرمت Sectionwise ممکن است به شکل زیر باشد:
چند خط اول با کامنت ها با کاراکتر % شروع می شود و وقتی به عنوان منحنی درون یابی وارد می شود نادیده گرفته می شود . اولین بخش حاوی داده ها در خط بعد از % Coordinates شروع می شود . بخش دوم حاوی داده ها در خط بعد از % Elements (بخش ها) شروع می شود . توجه داشته باشید که رشتههای مختصات و عناصر (بخشها) ضروری نیستند، اما فرض میشود که هر بخش حاوی دادهها بعد از هر بلوک نظرات شروع میشود، صرف نظر از اینکه بعد از کاراکتر % چه میآید . برای مثال، هنگام صادر کردن دادههای نمودار کانتور ، ممکن است بلوکهای بیشتری از داده وجود داشته باشد.
کد مثال زیر از یک جریان CsWriter برای نوشتن داده های منحنی درونیابی در یک فایل متنی استفاده می کند. یک مجموعه نقطه الگو p در یک الگوی دایرهای برای شعاع R داده شده و تعداد کپیهای n_of_copies کپی میشود .
محتویات بافر جریان کاراکتر را در فایل می نویسد و بافر را خالی می کند اما جریان را برای همیشه نمی بندد. در این مرحله، همچنان می توانید داده های بیشتری را در جریان بنویسید.
جریان را برای همیشه می بندد. اگر می خواهید داده های اضافی روی فایل بنویسید، باید جریان را دوباره باز کنید و داده های اضافی را اضافه کنید.
همانطور که در بالا برای شی Reader توضیح داده شد ، می توانید با استفاده از Ctrl+Space، ببینید کدام روش های اضافی برای شی نویسنده در دسترس هستند ، همانطور که در شکل زیر نشان داده شده است.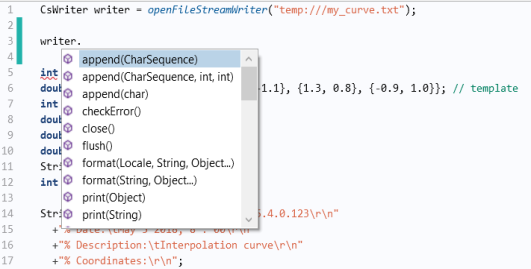
میتوانید با انتخاب گزینه Sectionwise برای قالب داده ، دادههای درونیابی حاصل را به عنوان یک منحنی درون یابی وارد کنید . این را می توان برای یک شی هندسی دو بعدی یا برای یک صفحه کار به صورت سه بعدی انجام داد. شکل زیر داده های وارد شده به یک مدل دو بعدی را نشان می دهد.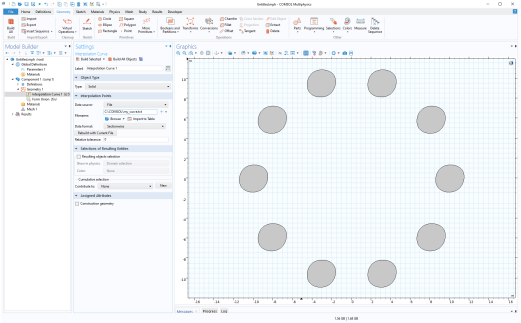
شما با استفاده از متدهای کلاس CsBinaryWriter ، داده ها را در یک فایل باینری می نویسید ، به گونه ای که تا حدودی شبیه به نوشتن متن با استفاده از CsWriter است. با این حال، به جای نوشتن رشته ها و کاراکترها، شما در حال نوشتن بایت هستید. برای مشاهده اینکه هر نوع داده به چند بایت نیاز دارد، به جدول در بخش «انواع داده اولیه» در صفحه 8 مراجعه کنید.
کد مثال زیر داده های نقطه سه بعدی تصادفی را در یک فایل باینری می نویسد. هر مختصات نقطه ای به صورت دوتایی ذخیره می شود و ذخیره آن 8 بایت طول می کشد. 4 بایت اول فایل تعداد نقاط فایل را به صورت int ذخیره می کند.
برای تبدیل راحت بین انواع داده های معمولی، مانند آرایه های دوگانه ، int و بایتی ، به روش کتابخانه Java® java.nio.ByteBuffer نیاز است. این روش بخشی از روشهای استاندارد موجود در ویرایشگر روش نیست و شما باید از نام کلاس Java® کاملاً واجد شرایط java.nio.ByteBuffer استفاده کنید ، همانطور که در کد مثال زیر نشان داده شده است.
حلقه for N نقطه ایجاد می کند و هر مختصات x -، y – و z را به صورت دوتایی با استفاده از یک آرایه بایت بایت 8 به طول 8 می نویسد.
جریان بایت را ببندید و یک مرورگر فایل را به کاربر نمایش دهید تا مکانی را برای ذخیره فایل باینری انتخاب کند.
بر اساس فرمت داده های مثال قبلی، کد زیر یک فایل باینری مربوطه را می خواند و نقاط را به عنوان داده های نقطه سه بعدی ترسیم می کند.
یک جریان بایت Java® را بر اساس فایل اعلان فایل 1 باز می کند ، که معمولاً در یک شی از فرم مرورگر فایل ارجاع می شود، مانند مثال های قبلی در مورد خواندن فایل های متنی.
حلقه for زیر تکه های 8 بایتی را در آرایه بایت bytes8 می خواند ، آنها را تبدیل می کند و نتایج را در یک آرایه دوبعدی p ذخیره می کند.
آخرین بخش از کد نمونه داده ها را ترسیم می کند و شبیه به مثال “خواندن فایل های ماتریس” در صفحه 177 است.



