
پنجره تنظیمات گره های مرحله مطالعه شامل بخش های زیر است (علاوه بر تنظیمات مطالعه خاص برای هر نوع مرحله مطالعه):
نوار ابزار ویندوز تنظیمات مراحل مطالعه
در بالای پنجرههای تنظیمات مراحل مطالعه ، یک نوار ابزار حاوی دستورات زیر است:
|
•
|
برای محاسبه کل مطالعه روی Compute ( ) کلیک کنید یا F8 را فشار دهید.
|
|
•
|
روی Update Solution ( ) کلیک کنید
|
تنظیمات مطالعه
شامل چک باکس هندسی غیرخطی
اگر مجوزی برای ماژول آکوستیک، ماژول MEMS یا ماژول مکانیک سازه (شامل هر ماژول الحاقی مانند ماژول غیرخطی مصالح سازه ای) دارید و مدل شما شامل مکانیک سازه می شود، بخش تنظیمات مطالعه شامل بررسی غیرخطی بودن هندسی است . جعبه
چک باکس Include geometric nonlinearity را انتخاب کنید تا یک تحلیل هندسی غیرخطی برای مرحله مطالعه فعال شود. برخی از طرحهای فیزیک تجزیه و تحلیل غیرخطی هندسی را تحمیل میکنند، که در این صورت نمیتوان تیک گزینه Include geometric nonlinearity را پاک کرد. برای جزئیات بیشتر، بخش های تئوری رابط فیزیک مربوطه را در کتابچه راهنمای ماژول های قابل اجرا ببینید.
نتایج در حین حل
کادر Plot را انتخاب کنید تا بتوان نتایج را در حین حل در پنجره گرافیکی ترسیم کرد . سپس از لیست گروه Plot چه چیزی را رسم کنید و برای شبیه سازی های وابسته به زمان، مراحل زمانی برای به روز رسانی نمودار را انتخاب کنید: زمان های خروجی یا گام های زمانی برداشته شده توسط حل کننده. نرم افزار مجموعه داده گروه نمودار انتخابی را به محض در دسترس قرار گرفتن نتایج ترسیم می کند. شما همچنین می توانید کنترل کنید که کدام کاوشگر مقادیر را جدول بندی و رسم کنید. پیش فرض این است که مقادیر را از تمام پروب ها در پنجره Table و پنجره Probe Plot جدول بندی و رسم کنید .
از فهرست Probes برای انتخاب هر پروب برای ارزیابی استفاده کنید . پیشفرض All است که همه پروبها را برای ترسیم و جدولبندی دادههای پروب انتخاب میکند. برای باز کردن فهرستی با تمام کاوشگرهای موجود دستی را انتخاب کنید . از دکمه های Move Up (  )، Move Down (
)، Move Down (  )، Delete (
)، Delete (  ) و Add ( ) استفاده کنید
) و Add ( ) استفاده کنید  تا لیست حاوی پروب هایی باشد که می خواهید نتایج را در حین حل مشاهده کنید. هیچکدام را انتخاب کنید تا هیچ کاوشگری شامل نشود.
تا لیست حاوی پروب هایی باشد که می خواهید نتایج را در حین حل مشاهده کنید. هیچکدام را انتخاب کنید تا هیچ کاوشگری شامل نشود.
|
|
برای مثال میتوانید از پروبها برای جدولبندی مقادیر مورد نظر در طول یک شبیهسازی پارامتری بزرگ استفاده کنید. پس از آن می توان تنها آخرین راه حل را در حافظه در طول جاروب پارامتری نگه داشت، که به طور بالقوه می تواند نیازهای حافظه و زمان شبیه سازی را به میزان قابل توجهی کاهش دهد.
|
فیزیک و انتخاب متغیرها
برای کسب اطلاعات دقیق در مورد این بخش، گزینه Physics and Variables Selection را ببینید . میتوانید موارد مختلفی را کنترل و تعیین کنید که رابط فیزیک برای حل آنها متفاوت است، یا برای موارد تجزیه و تحلیل مختلف، از کدام متغیرها و ویژگیهای فیزیکی (مثلاً شرایط مرزی و منابع) استفاده کنید. پیشفرض این است که برای تمام رابطهای فیزیک که با نوع مرحله مطالعه سازگار هستند، حل شود.
مقادیر متغیرهای وابسته
هنگامی که در یک مرحله مطالعه رابط های فیزیکی دارید که آنها را حل نمی کنید اما درجاتی از آزادی را فراهم می کند، می توانید مشخص کنید که نرم افزار COMSOL Multiphysics چگونه مقادیر چنین درجاتی از آزادی (متغیرهای وابسته) را مدیریت می کند.
تنظیمات در این بخش تعیین می کند که چگونه حل کننده متغیرهای وابسته ای را که شما آنها را حل نمی کنید کنترل می کند. برای مثال، در پیکربندی حلکننده که در آن شما فقط زیرمجموعهای از متغیرهای وابسته را در هر مرحله حل میکنید، کاربرد دارد. همچنین می توانید مقادیر اولیه متغیرهایی را که حل می کنید مشخص کنید.
بهطور پیشفرض، نرمافزار COMSOL Multiphysics این مقادیر را بهصورت اکتشافی، بسته به فیزیک، بهعنوان مثال، مقادیر اولیه مشخص شده یا راهحلی از مرحله مطالعه قبلی تعیین میکند. در قسمت مقادیر اولیه متغیرهای حل شده برای ، مقدار پیشفرض فهرست تنظیمات ، Physics controlled است . برای تعیین مقادیر اولیه متغیرهای وابسته ای که برای آنها حل می کنید، User controlled را از لیست تنظیمات انتخاب کنید .
|
|
مقادیر اولیه متغیرهای حل شده برای تنظیمات هیچ تاثیری در هنگام استفاده از حل کننده مقدار ویژه ندارند.
|
به طور مشابه، برای تعیین مقادیر متغیرهای وابسته ای که آنها را حل نمی کنید، از لیست تنظیمات در قسمت مقادیر متغیرهای حل نشده، User controlled را انتخاب کنید .
سپس از لیست روش برای تعیین نحوه محاسبه مقادیر اولیه متغیرهای حل شده برای و مقادیر متغیرهای حل نشده استفاده کنید. انتخاب کنید:
|
•
|
عبارت اولیه برای استفاده از عبارات مشخص شده در گره های مقادیر اولیه برای رابط فیزیک در مدل.
|
|
•
|
راه حل برای استفاده از مقادیر اولیه همانطور که توسط یک شی راه حل مشخص شده است (راه حلی از مرحله مطالعه).
|
از لیست مطالعه برای تعیین اینکه از چه مطالعه ای استفاده کنید استفاده کنید :
|
•
|
حل صفر را انتخاب کنید تا همه متغیرها صفر شوند.
|
|
•
|
هر مطالعه موجود دیگری را برای استفاده از آن به عنوان مقدار اولیه انتخاب کنید.
|
سپس از لیست Solution استفاده کنید تا مشخص کنید اگر Study روی یک مطالعه تنظیم شده باشد، از چه شی راه حلی استفاده شود :
|
–
|
فعلی برای استفاده از راه حل فعلی.
|
|
–
|
هر شی راه حل موجود دیگری که از آن به عنوان مقدار اولیه استفاده شود.
|
بسته به شی راه حل مورد استفاده، می توانید راه حل های مختلفی را برای استفاده انتخاب کنید. اگر یک راه حل دارای گره هایی برای ذخیره راه حل ها در توالی خود باشد، می توانید با استفاده از لیست Use انتخاب کنید که از کدام راه حل استفاده کنید . مقدار Current مقداری است که راه حل در لحظه خواندن مقدار دارد. مقادیر دیگر مقادیر ذخیره شده در گره های مربوطه دنباله هستند. برای وارد کردن فهرست راه حلی که می خواهید استفاده کنید، Manual را انتخاب کنید . این شاخص می تواند یک پارامتر سراسری باشد که در یک جابجایی پارامتری با ورودی شماره حل به آن جارو می شود.
بسته به نوع مطالعه راه حلی که انتخاب کرده اید، می توانید راه حل های مختلفی را از فهرستی در زیر لیست مطالعه (و لیست های راه حل و استفاده در صورت وجود) انتخاب کنید:
برای مطالعه ثابت ، از لیست انتخاب ، یکی از گزینه های زیر را انتخاب کنید:
|
•
|
خودکار (تک راه حل) (پیش فرض) برای انتخاب یک راه حل در گره متغیرهای وابسته بسته به ارزیابی کلی برای یافتن مقدار فعلی پارامترها در راه حل ورودی یا در صورت عدم امکان، آخرین (معمولاً تنها) راه حل.
|
|
•
|
خودکار (همه راه حل ها) برای استفاده از همه (معمولاً فقط یک) راه حل های آن مطالعه (برای جزئیات بیشتر به زیر مراجعه کنید).
|
|
•
|
ابتدا از اولین (معمولاً تنها) راه حل استفاده کنید
|
|
•
|
آخرین برای استفاده از آخرین (معمولا تنها) راه حل، از لیست را انتخاب کنید تا راه حل ها را از یک لیست انتخاب کنید.
|
|
•
|
درون یابی برای تعیین یک مقدار درون یابی در قسمت متن زیر.
|
|
•
|
راهنمای استفاده از شماره راه حل خاصی که در قسمت Index مشخص کرده اید .
|
|
•
|
1 برای استفاده از اولین (معمولا تنها) راه حل. اگر از ادامه پارامتریک مطالعه ثابت استفاده می کنید، می توانید راه حل های دیگری را انتخاب کنید.
|
برای مطالعه وابسته به زمان ، از لیست زمان ، یکی از گزینه های زیر را انتخاب کنید:
|
•
|
خودکار (تک راه حل) (پیش فرض) برای انتخاب یک راه حل در گره متغیرهای وابسته بسته به یک ارزیابی کلی برای یافتن مقدار فعلی پارامترها در راه حل ورودی یا در صورت عدم امکان، راه حل برای آخرین بار.
|
|
•
|
خودکار (همه راه حل ها) برای استفاده از همه راه حل های آن مطالعه (برای جزئیات بیشتر به زیر مراجعه کنید).
|
|
•
|
ابتدا از راه حل اول استفاده کنید.
|
|
•
|
آخرین استفاده از آخرین راه حل.
|
|
•
|
درون یابی برای تعیین زمان در قسمت متن زیر.
|
|
•
|
راهنمای استفاده از شماره راه حل خاصی که در قسمت Index مشخص کرده اید .
|
|
•
|
یکی از زمان های خروجی برای استفاده از راه حل در آن زمان.
|
برای مطالعه مقدار ویژه یا فرکانس ویژه ، از لیست مقادیر ویژه ، یکی از گزینه های زیر را انتخاب کنید:
|
•
|
خودکار (تک راه حل) (پیش فرض) برای انتخاب یک راه حل در گره متغیرهای وابسته بسته به ارزیابی کلی برای یافتن مقدار فعلی پارامترها در راه حل ورودی یا در صورت عدم امکان، برای استفاده از راه حل برای حل اول مقدار ویژه یا فرکانس ویژه و محلول ویژه مرتبط با آن.
|
|
•
|
خودکار (همه راه حل ها) برای استفاده از همه راه حل های آن مطالعه (برای جزئیات بیشتر به زیر مراجعه کنید).
|
|
•
|
ابتدا از راه حل اول استفاده کنید.
|
|
•
|
آخرین استفاده از آخرین راه حل.
|
|
•
|
درون یابی برای تعیین یک مقدار ویژه از فرکانس ویژه در فیلد متن زیر.
|
|
•
|
راهنمای استفاده از شماره راه حل خاصی که در قسمت Index مشخص کرده اید .
|
|
•
|
یکی از مقادیر ویژه برای استفاده از راه حل برای حل ویژه مربوطه.
|
برای مطالعه پارامتریک یا دامنه فرکانس ، از لیست مقدار پارامتر ، یکی از گزینه های زیر را انتخاب کنید:
|
•
|
خودکار (تک راه حل) (پیش فرض) برای انتخاب یک راه حل در گره متغیرهای وابسته بسته به ارزیابی کلی برای یافتن مقدار فعلی پارامترها در راه حل ورودی یا در صورت عدم امکان، راه حل برای آخرین مقدار پارامتر مجموعه یا فرکانس
|
|
•
|
خودکار (همه راه حل ها) برای استفاده از همه راه حل های آن مطالعه (برای جزئیات بیشتر به زیر مراجعه کنید).
|
|
•
|
ابتدا از راه حل اول استفاده کنید.
|
|
•
|
آخرین استفاده از آخرین راه حل.
|
|
•
|
درون یابی برای تعیین زمان در قسمت متن زیر.
|
|
•
|
راهنمای استفاده از شماره راه حل خاصی که در قسمت Index مشخص کرده اید .
|
|
•
|
یکی از مقادیر پارامتر یا فرکانس ها برای استفاده از راه حل مربوطه.
|
برای گزینه خودکار (همه انتخاب ها) ، همه راه حل ها به حل کننده منتقل می شوند و حل کننده مقادیر اولیه را بر اساس وجود مطابقت با پارامتر فعلی تاپل انتخاب می کند. این امکان ارسال مقادیر یا حدس های اولیه چندگانه به حل کننده را فراهم می کند، که اگر در حال انجام یک مطالعه پارامتری با استفاده از پارامترهای متعدد هستید و همگرایی هر تاپل پارامتر به یک حدس اولیه خوب بستگی دارد، می تواند مفید باشد. همچنین می تواند همراه با حل کننده پارامتری وابسته به زمان برای استفاده از مقادیر اولیه متفاوت برای هر تاپل پارامتر استفاده شود.
در قسمت Store fields in output ، میتوانید تعیین کنید که متغیرهای فیلدی که فقط برای برخی از بخشهای هندسه حل میکنید ذخیره شوند (مثلاً اگر راهحل موجود در دامنه مورد علاقه نیست، یک مرز). شما قسمت هایی از هندسه را که فیلدها را به عنوان گره های انتخاب ذخیره کنید، تعریف می کنید. از فهرست تنظیمات ، همه (پیشفرض) را انتخاب کنید تا همه فیلدها در تمام قسمتهای هندسه که در آن تعریف شدهاند ذخیره شوند، یا برای انتخابها برای انتخاب یک یا چند انتخاب که به لیست اضافه میکنید، انتخاب کنید. روی دکمه افزودن ( ) کلیک کنید  تا کادر محاوره ای افزودن که شامل تمام انتخاب های موجود است باز شود. انتخاب هایی را که می خواهید اضافه کنید انتخاب کنید و سپس روی OK کلیک کنید. همچنین می توانید با استفاده از دکمه Delete ( ) انتخاب ها را از لیست حذف کنید
تا کادر محاوره ای افزودن که شامل تمام انتخاب های موجود است باز شود. انتخاب هایی را که می خواهید اضافه کنید انتخاب کنید و سپس روی OK کلیک کنید. همچنین می توانید با استفاده از دکمه Delete ( ) انتخاب ها را از لیست حذف کنید  و با استفاده از دکمه های Move Up (
و با استفاده از دکمه های Move Up (  ) و Move Down (
) و Move Down (  ) آنها را جابه جا کنید. گره فیلد را نیز ببینید ، که در آن میتوانید کنترل کنید چه چیزی در خروجی ذخیره شود، اگر متغیرهای وابسته مربوطه از تنظیمات تعریفشده توسط کاربر استفاده میکنند.
) آنها را جابه جا کنید. گره فیلد را نیز ببینید ، که در آن میتوانید کنترل کنید چه چیزی در خروجی ذخیره شود، اگر متغیرهای وابسته مربوطه از تنظیمات تعریفشده توسط کاربر استفاده میکنند.
|
|
اگر از For Selection استفاده می کنید و راه حل را فقط برای برخی از قسمت های هندسه ذخیره می کنید، ادامه با یک مرحله مطالعه دیگر امکان پذیر نیست.
|
انتخاب مش
مشخص کنید – برای هر هندسه – از کدام شبکه برای مرحله مطالعه استفاده کنید. برای هر هندسه فهرست شده در ستون Component ، یک مش را از لیست مش های موجود در ستون Mesh انتخاب کنید . هر لیست مش ها شامل مش های تعریف شده برای هندسه ای است که در همان ردیف پیدا می کنید.
انطباق و برآورد خطا
اینها تنظیماتی برای انطباق مش و برآورد خطا هستند که برای مراحل مطالعه ثابت، فرکانس ویژه، ارزش ویژه و دامنه فرکانس در دسترس هستند. سازگاری مش (با تنظیمات و عملیات دیگر) برای مراحل مطالعه وابسته به زمان نیز موجود است. به زمان وابسته و اصلاح مش تطبیقی (انطباق وابسته به زمان) مراجعه کنید . بسته به نوع انطباق، توالی های مش بندی برای اصلاحات مش تطبیقی، با استفاده از گره های Adapt یا Size Expression و راه حل های مربوطه برای بازرسی و اصلاحات احتمالی ایجاد می شوند. برآوردهای خطا به عنوان متغیرهایی برای پس پردازش در دسترس هستند (به عنوان مثال، freq.errtotبرای برآورد کل خطا در مطالعه دامنه فرکانس). راهحلهای اصلاح مش تطبیقی در یک مجموعه داده راه حل جداگانه در دسترس میشوند ( مثلاً مطالعه 1/راهحلهای اصلاح مش تطبیقی 1 ). هنگام استفاده از این مجموعه داده برای پس پردازش، میتوانید از هر یک از راهحلهای موجود برای اصلاح مش تطبیقی از فهرست انتخاب پارامتر (سطح اصلاح) استفاده کنید . تنظیمات اضافی در زیرگره های Adaptive Mesh Refinement (Stationary and Eigenvalue Adaptation) و Error Estimation در زیر گره حل کننده در پیکربندی های حل کننده موجود است .
از لیست انطباق و برآورد خطا ، اگر میخواهید از تخمین خطا استفاده کنید، تخمینهای خطا را انتخاب کنید یا اگر میخواهید از پالایش مش تطبیقی استفاده کنید، برآوردهای انطباق و خطا را انتخاب کنید. در مورد دوم، تخمین های خطا که در الگوریتم تطبیق استفاده می شود نیز برای پس پردازش در دسترس هستند. هیچ کدام را برای عدم تطبیق یا تخمین خطا انتخاب کنید . نام داخلی پارامتر سطح پالایش adaptlevel است . برای جداسازی محلولها برای مشهای مختلف، با روش حلکننده سازگاری اضافه میشود. در صورتی که یک پارامتر تعریف شده توسط کاربر با آن نام در مدل وجود داشته باشد، یک نام منحصر به فرد برای پارامتر سطح پالایش با افزودن یک رقم به سطح تطبیق ایجاد می شود.. میتوانید از آن برای دسترسی به راهحلها از سطوح مختلف پالایش مش با استفاده از عملگر withsol() استفاده کنید . به عنوان مثال، با استفاده از نحو زیر: withsol(‘sol1’, expr ,setval(adaptlevel,2)) برای ارزیابی یک عبارت expr با محلول موجود در sol1 برای سطح تطبیق مش 2.
|
|
|
این نرم افزار اصلاح مش تطبیقی را تنها در یک هندسه انجام می دهد. از فهرست تطبیق در هندسه برای مشخص کردن هندسه استفاده کنید . اگر نمیخواهید تطبیق مش را در کل هندسه انجام دهید، از تنظیمات موجود در بخش انتخاب موجودیت هندسی برای تطبیق در زیر استفاده کنید.
از فهرست برآورد خطا برای کنترل نحوه محاسبه تخمین خطا استفاده کنید :
|
•
|
L2 هنجار خطای مربع را انتخاب کنید تا از هنجار مربع L2 خطا استفاده کنید. این تنها گزینه برای مطالعات Eigenvalue است. در گره Error Estimation در زیر گره Stationary Solver ، از فیلد Scaling factor برای وارد کردن یک لیست جدا شده از فاکتورهای مقیاسبندی، یکی برای هر متغیر فیلد (پیشفرض: 1) استفاده کنید . تخمین خطا برای هر متغیر فیلد بر این عامل تقسیم می شود. همچنین، تخمین خطای نرمال L 2 بر اساس برآورد پایداری برای PDE است. همچنین در گره Error Estimation از ترتیب مشتق تخمین ثبات استفاده کنیدفیلد برای تعیین ترتیب آن (پیشفرض: 2). برای مسائل خاصی که متقارن هستند و در جایی که تخمین های خطای قوی وجود دارد، این روش معادل یک تخمین خطای عملکردی است که تابعی آن هنجار L2 حل شده است. این روش را می توان برای مشکلاتی که این مفروضات معتبر نیستند نیز استفاده کرد، اما در آن صورت انطباق بهینه نخواهد بود. برای اطلاعات بیشتر در مورد این تنظیمات به موارد زیر مراجعه کنید.
|
هنجار L2 روش مربع خطا، خطا را برای یک عنصر مش به عنوان مجموع مشارکت برای معادلات مختلف حل شده تخمین می زند. خلاصه می شود
که در آن A مساحت عنصر (حجم، طول)، h اندازه عنصر، q مرتبه مشتق تخمین پایداری ، s ضریب مقیاس و ρ تخمینی از باقیمانده PDE است. رفتار مجانبی ρ این است که با h p متناسب است ، جایی که p ترتیب باقیمانده است (به زیر مراجعه کنید). حتی اگر بتوان مقدار واقعی ρ را به طور کلی تخمین زد، کمک به الگوریتم با این ترتیب مهم است – به عنوان مثال، برای روش انتخاب عنصرحداقل جهانی تقریبی (در زیرگره اصلاح مش تطبیقی ؛ به اصلاح مش تطبیقی (تطبیق ثابت و مقدار ویژه) مراجعه کنید)، که اساساً یک مسئله بهینه سازی را برای مکان پالایش حل می کند به طوری که خطای کل تا حد امکان کاهش می یابد (محدود به تعداد عناصر). که می توان اضافه کرد). همه مقادیر ترتیب مشتق تخمین ثبات ، ضریب مقیاس و ترتیب باقیمانده ( به ترتیب q ، s و p ، در زیرگره تخمین خطا ؛ برآورد خطا را ببینید ) همگی می توانند به عنوان بردار برای معادلات مختلف داده شوند. برایترتیب مشتق تخمین پایداری ، پیشفرض 2 است و به تخمین پایداری مربوط میشود که برای مسئله مورد نظر صادق است. اگر از نوع پواسون نیست، ممکن است نیاز به تنظیم داشته باشد. برای ضریب مقیاسبندی ، پیشفرض 1 است. عمدتاً وزن کردن نسبتاً در بخشهای مختلف معادلات حلشده مهم است، به این معنی که به طور کلی باید یک آرایه اعداد جدا شده با فاصله ارائه کنید. توجه داشته باشید که هنگام حل یک مسئله چندفیزیکی، جمع بر روی معادلات مختلف واحد یکسانی نخواهد داشت زیرا ρ متفاوت است.واحدهای مختلفی خواهد داشت. بنابراین، اولین تلاش برای مقیاسبندی، در نظر گرفتن این است. در واقع، حتی یک مورد فیزیک منفرد مانند جریان سیال، این واحد جمع را سازگار نمیسازد، زیرا باقیمانده برای اندازهگیری تکانه و جرم با ضرایب مقیاسبندی پیشفرض 1 جمع میشود. برای ترتیب باقیمانده، پیشفرض یک مرتبه کمتر است . از توابع شکل استفاده شده برای معادله. این را فقط برای PDE های غیر استاندارد تغییر دهید. به طور کلی، ترتیب مورد انتظار مرتبه پایه منهای بالاترین مرتبه مشتق فضایی در فرمول ضعیف است. برای یک فرمول PDE مرتبه دوم با ادغام قطعات (کاهش تمام مشتقات مرتبه دوم به مرتبه اول) این فرمول مرتبه یک خواهد بود.
|
•
|
Functional را انتخاب کنید و یک نوع Functional را مشخص کنید . انواع عملکردی موجود از پیش تعریف شده و دستی هستند . این گزینه مش را با دقت بهبود یافته در بیان عملکرد (مثلاً مقداری انرژی، کشیدن یا بلند کردن) تطبیق می دهد. دستی را انتخاب کنید تا در فیلد Functional یک عبارت با ارزش اسکالر در دسترس جهانی را مشخص کنید (به عنوان مثال، نام یک پروب متغیر جهانی). اگر Predefined را انتخاب کنید ، می توانید از لیست از پیش تعریف شده عملکردی از لیست عملکردی Solution انتخاب کنید :
|
|
–
|
انتگرال (پیش فرض)
|
|
–
|
هنجار L2
|
|
–
|
هنجار L1
|
|
–
|
حداکثر هنجار تقریبی
|
برای یک آمار مرحله مطالعه ثابت ، یک متغیر سراسری برای تابع با نام stat.gfunc (و به طور مشابه برای مرحله مطالعه دامنه فرکانس) تعریف شده است. عملکرد را می توان در Results>Derive Values با افزودن یک گره Global Evaluation و در بخش Expressions در پنجره تنظیمات آن، انتخاب Global Definitions> Error estimation>stat.gfunc – Functional – Stationary ارزیابی کرد .
تابع باید قابل تمایز (یا تحلیلی با ارزش پیچیده) باشد. همچنین عبارات موجود در فرمول باید قابل تمایز باشند. اگر این مورد برقرار نباشد، راه حل الحاقی و تخمین خطای آن خطر دقیق نبودن دارد، و سپس انطباق برای عملکرد مورد استفاده بهینه نخواهد بود. گزینه Functional خطای یک عنصر مش را به عنوان مجموع مشارکت ها تخمین می زند. بر روی A ω K ρ جمع می شود ، جایی که ω K از راه حل الحاقی (یا دوگانه) محاسبه می شود. ω K را می توان با روش های مختلف محاسبه کرد ( PPR برای لاگرانژ یا خطای درون یابی ). معادله 20-5 در مورد چگونگی ω استK برای PPR برای لاگرانژ محاسبه می شود . توجه داشته باشید که این روش از عوامل مقیاسبندی یا ترتیب مشتق تخمین ثبات استفاده نمیکند، زیرا آنها بخشی از فرمول نیستند (آنها در ω K ساخته شدهاند ). اما ρ بخشی از فرمول است و بنابراین ترتیب باقیمانده می تواند مهم باشد (به عنوان مثال، برای روش حداقل جهانی خشن ؛ به اصلاح مش تطبیقی (تطبیق ثابت و مقدار ویژه) مراجعه کنید ). برای حداکثر هنجار تقریبی ، p -norm مرتبه بالا . دلیل این امر این است که می توان این عملکرد را متمایز کرد.
|
•
|
برای تعیین نشانگر خطا با استفاده از عبارت خطا، نشانگر خطا را انتخاب کنید، که با استفاده از دکمه افزودن ( ) به جدول عبارت خطا در زیر اضافه می کنید . عبارت خطا می تواند هر عبارتی، از جمله متغیرهای فیلد و مشتقات آنها، تعریف شده در دامنه باشد. این روش مش را در جایی که عبارت خطا بزرگ می شود تطبیق می دهد. سازگاری معمولاً مطلوب نیست. چک باکس Active را برای عبارات خطا که باید بخشی از نشانگر خطا باشد، انتخاب کنید . از Move Up ( )، Move Down ( ) و Delete (
|
از لیست متغیرهای تخمین خطا افزودن (اگر نشانگر خطا را از فهرست تخمین خطا در بالا انتخاب کرده باشید، در دسترس نیست )، متغیرهایی را برای ذخیره در صورت وجود انتخاب کنید:
|
•
|
برآورد خطا و باقیمانده را برای ذخیره همه متغیرها (پیش فرض) انتخاب کنید .
|
|
•
|
تخمین خطا را انتخاب کنید تا فقط متغیرها برای تخمین خطا ذخیره شوند.
|
|
•
|
هیچ کدام را انتخاب کنید تا هیچ متغیری ذخیره نشود، که ممکن است منجر به بهبود عملکرد شود.
|
چک باکس Save solution on every mesh adapted به صورت پیش فرض انتخاب می شود. اگر نمیخواهید محلول را روی هر مش سازگار ذخیره کنید، این کادر را پاک کنید. در آن صورت، دو راه حل آخر (بهترین و بهترین راه حل دوم) بدون توجه به تعداد کل راه حل ها ذخیره می شوند.
تحت Mesh adaptation ، تنظیمات زیر در دسترس هستند.
از فهرست روش تطبیق برای کنترل نحوه اصلاح تطبیقی عناصر مش استفاده کنید . یکی از این روش ها را انتخاب کنید:
|
•
|
اصلاح عمومی ، برای استفاده از مش فعلی به عنوان نقطه شروع و اصلاح آن با اصلاح، درشت کردن، اصلاح توپولوژی و هموارسازی نقطه. برای کنترل اینکه آیا از درشت کردن مش استفاده می شود، از کادر بررسی Allow coarsening استفاده کنید . اگر مش حاوی عناصر ناهمسانگرد باشد (مثلاً یک شبکه لایه مرزی)، بهتر است برای حفظ ساختار ناهمسانگرد، درشت شدن مش را غیرفعال کنید. اگر اجازه درشت کردن را انتخاب کرده اید، حداکثر ضریب درشت شدن (مقدار 5 به طور پیش فرض) را تعیین کنید تا اندازه مش تصفیه شده در مناطقی که نیازی به پالایش نیست، مقیاس شود.
|
|
•
|
Rebuild mesh ، برای تنظیم یک عبارت اندازه که خطا را توصیف می کند و با استفاده از عبارت اندازه به عنوان ورودی، دنباله مش بندی را بازسازی می کند. توجه داشته باشید که مش های ساختاریافته، مانند مش های نگاشت شده و جارو شده، به طور کلی به درستی اصلاح نمی شوند. این روش در مش های وارداتی پشتیبانی نمی شود. اندازه مش تصفیه شده حداقل اندازه مش اصلی (مش تصفیه شده قبلی) و اندازه تعیین شده توسط پالایش است. حداکثر ضریب درشت شدن (مقدار 3 به طور پیش فرض) را تعیین کنید تا اندازه مش تصفیه شده در مناطقی که نیازی به پالایش نیست، مقیاس شود.
|
|
•
|
پالایش منظم ، برای اینکه حلکننده عناصر را در یک الگوی منظم با نصف کردن تمام لبههای عنصری که نیاز به پالایش دارد، اصلاح کند.
|
|
•
|
پالایش طولانیترین لبه ، برای اینکه حلکننده تنها طولانیترین لبه یک عنصر را با نیمنصفکردن بازگشتی طولانیترین لبه عناصر لبهای که نیاز به اصلاح دارند، اصلاح کند. این روش کمتر برای مدل هایی با عناصر غیرساده مناسب است. این روش پیش فرض است.
|
با تنظیمات موجود در لیست خاتمه هدف گرا، شما یا رابط های فیزیکی می توانید تعدادی از کمیت های هدف گرا کلی اضافه کنید تا زمانی که این مقادیر به جای یک تعداد ثابت تکرار تطبیق پایدار باشند، زمانی که این مقادیر به دقت درخواستی ثابت هستند، انطباق مش پایان می یابد. برای کنترل، خاموش (پیشفرض)، خودکار یا دستی را انتخاب کنید . شما، زمانی که لیست روی دستی یا فیزیک، وقتی لیست روی خودکار تنظیم شده است، میتواند تعدادی از کمیتهای هدفمحور جهانی را اضافه کند، و زمانی که این مقادیر به دقت درخواستی پایدار باشند، انطباق مش پایان مییابد. این کمیتهای هدفگرا میتوانند، برای مثال، برای یک شبیهسازی RF، پارامترهای S یا کمیت دیگر مورد علاقه باشند. خاتمه هدف گرا را می توان با هر یک از روش های برآورد خطای موجود استفاده کرد. هنگامی که لیست پایان هدف گرا روی دستی تنظیم می شود ، می توانید عبارات پایانه هدف گرا را در جدول پایین این بخش اضافه کنید. روی دکمه افزودن ( ) کلیک کنید  تا یک عبارت (پیشفرض: 1) را اضافه کنید که میتوانید آن را در ستون عبارت پایان هدفگرا ویرایش کنید . در صورت تمایل، تلرانس (پیشفرض: 0.01) را در Tolerance تنظیم کنیدستون، و نوع تحمل در ستون نوع تحمل : نسبی (پیشفرض) یا مطلق . از دکمه های Active برای مدیریت عبارات پایان هدف گرا استفاده کنید . انطباق مش تا زمانی اجرا می شود که تغییرات نسبی برای همه عبارات (به صورت جداگانه برای همه عبارات اعمال می شود) به زیر آستانه مربوطه خود بروند، مگر اینکه حداکثر تعداد انطباق ها رعایت شود، در این صورت الگوریتم با یک هشدار خاتمه می یابد.
تا یک عبارت (پیشفرض: 1) را اضافه کنید که میتوانید آن را در ستون عبارت پایان هدفگرا ویرایش کنید . در صورت تمایل، تلرانس (پیشفرض: 0.01) را در Tolerance تنظیم کنیدستون، و نوع تحمل در ستون نوع تحمل : نسبی (پیشفرض) یا مطلق . از دکمه های Active برای مدیریت عبارات پایان هدف گرا استفاده کنید . انطباق مش تا زمانی اجرا می شود که تغییرات نسبی برای همه عبارات (به صورت جداگانه برای همه عبارات اعمال می شود) به زیر آستانه مربوطه خود بروند، مگر اینکه حداکثر تعداد انطباق ها رعایت شود، در این صورت الگوریتم با یک هشدار خاتمه می یابد.
از قسمت Maximum number of adaptations برای تعیین حداکثر تعداد تکرارهای اصلاح مش تطبیقی استفاده کنید . مقدار پیش فرض 5 در 1D، 2 در 2D و 1 در 3D است. با تنظیم پایان هدف گرا روی خودکار ، مقدار پیش فرض روی 20 در 1 بعدی، 15 در 2 بعدی و 10 در سه بعدی تنظیم می شود.
با تنظیم پایان هدفمحور روی خودکار یا دستی ، میتوانید نمایش همگرایی را از روی تطبیق زمانی که کادر بررسی افزایشهای خاتمه هدفمحور خروجی انتخاب شده است، کنترل کنید. می توان پنجره نمودار را برای نمایش همگرایی و همچنین جدول مورد استفاده توسط نمودار را از پنجره Plot انتخاب کرد – به ترتیب پنجره New (پیش فرض) یا Graphics – و لیست های جدول خروجی را انتخاب کنید . اگر New را از لیست جدول خروجی انتخاب کنید ، دو جدول جدید ایجاد می شود، یکی برای نمودار همگرایی تطبیقی و دیگری برای ارائه اطلاعات پرمخاطب.
همچنین سطح جزئیات گزارش را از فهرست گزارش پایان پایانی هدفگرا انتخاب کنید : حداقل ، عادی (پیشفرض)، یا تفصیلی . اگر میخواهید ارزیابیها برای همه پارامترها، فرکانسها یا مقادیر ویژه در گزارش لحاظ شود، جزئیات را انتخاب کنید .
برای تنظیمات بیشتر، به اصلاح مش تطبیقی (تطبیق ثابت و مقدار ویژه) مراجعه کنید .
متغیرهای سازگاری و تخمین خطا
جدول زیر شامل متغیرهایی است که در صورت فعال بودن انطباق و برآورد خطا در دسترس هستند. نام متغیرها برای یک مورد با حل آمار مرحله مطالعه ثابت برای متغیر وابسته u است .
|
نام متغیر
|
شرح
|
|
stat.errEst
|
مجموع خطا در تمام معادلات و عناصر جمع شده است. یک متغیر جهانی
|
|
stat.errEst.u
|
مجموع خطای مجموع تمام عناصر معادله یا متغیر u . یک متغیر جهانی
|
|
comp1.err.u
|
تخمین خطا برای معادله یا متغیر u در جزء comp1 . در هر عنصر مش ثابت است.
|
|
ایالت.errtot
|
سهم کل خطا از هر عنصر. مجموع خطاها بیش از همه معادلات حل شده است. در هر عنصر مش ثابت است.
|
انتخاب موجودیت هندسی برای انطباق
از لیست سطح موجودیت هندسی ، موجودیت هندسی را انتخاب کنید که میخواهید اصلاح مش تطبیقی را روی آن انجام دهید: هندسه کامل (پیشفرض)، دامنه ، مرز ، یا لبه (فقط سه بعدی). به عنوان مثال، انتخاب Boundary می تواند مفید باشد اگر مدل شامل یک رابط فیزیک تعریف شده بر روی مرزها (سطوح) باشد و بخواهید انطباق را بر اساس آن رابط فیزیک قرار دهید. برای همه سطوح به جز Entire geometry ، موجودیتهای هندسی را با استفاده از فهرست انتخاب و ابزار انتخاب زیر انتخاب کنید.
برنامه های افزودنی مطالعه
اینها برنامه های افزودنی برای حل کننده اصلی مطالعه هستند، مانند پالایش مش تطبیقی و مش بندی مجدد خودکار. گزینه ها بسته به نوع مطالعه متفاوت است.
جارو کمکی
برای فعال کردن یک جابجایی پارامتر کمکی ، که مربوط به گره ویژگی حلگر پارامتری است، کادر بررسی جابجایی کمکی را انتخاب کنید . برای هر مجموعه ای از مقادیر پارامتر، نوع Sweep انتخاب شده برای آن حل می شود. این برای مطالعات Stationary، Time Dependent و Frequency Domain در دسترس است.
یک نوع Sweep را برای تعیین نوع جارو کردن برای انجام انتخاب کنید:
|
•
|
ترکیبهای مشخص شده (پیشفرض) تعدادی از ترکیبهای داده شده از مقادیر را که برای هر پارامتر در لیست داده شده است، حل میکند. لیست پارامترها به ترتیب داده شده با هم ترکیب می شوند، یعنی ترکیب اول حاوی مقدار اول در هر لیست، ترکیب دوم شامل تمام مقادیر دوم و غیره است.
|
|
•
|
همه ترکیبات برای همه ترکیبات مقادیر حل می شود. یعنی تمام مقادیر برای هر پارامتر با تمام مقادیر سایر پارامترها ترکیب می شوند. استفاده از همه ترکیب ها می تواند به تعداد بسیار زیادی راه حل (برابر حاصل ضرب طول لیست های پارامترها) منجر شود.
|
در جدول، نام پارامتر ، لیست مقدار پارامتر و واحد پارامتر (اختیاری) را برای حل کننده پارامتری مشخص کنید. روی دکمه افزودن ( ) کلیک کنید  تا یک ردیف به جدول اضافه شود. هنگامی که برای تعریف مقادیر پارامتر روی ستون لیست مقدار پارامتر کلیک می کنید، روی دکمه Range (
تا یک ردیف به جدول اضافه شود. هنگامی که برای تعریف مقادیر پارامتر روی ستون لیست مقدار پارامتر کلیک می کنید، روی دکمه Range ( 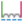 ) کلیک کنید تا محدوده ای از مقادیر پارامتر را تعریف کنید. واحد پارامتر واحد پارامتر سراسری را لغو می کند. اگر واحد پارامتری داده نشود، مقادیر پارامتر بدون ابعاد صریح بدون بعد در نظر گرفته می شود.
) کلیک کنید تا محدوده ای از مقادیر پارامتر را تعریف کنید. واحد پارامتر واحد پارامتر سراسری را لغو می کند. اگر واحد پارامتری داده نشود، مقادیر پارامتر بدون ابعاد صریح بدون بعد در نظر گرفته می شود.
|
|
اگر ترکیبات مشخص شده را انتخاب کنید ، لیست مقادیر باید طول مساوی داشته باشد.
|
یک جایگزین برای تعیین نام و مقادیر پارامترها به طور مستقیم در جدول، تعیین آنها در یک فایل متنی است. از دکمه Load from File (  ) برای مرور چنین فایل متنی استفاده کنید . نام ها و مقادیر خوانده شده به جدول فعلی اضافه می شوند. فرمت فایل متنی باید به گونه ای باشد که نام پارامترها در ستون اول و مقادیر هر پارامتر به صورت ردیفی با فاصله ای که نام و مقادیر را از هم جدا می کند و فاصله ای که مقادیر را از هم جدا می کند ظاهر شود.
) برای مرور چنین فایل متنی استفاده کنید . نام ها و مقادیر خوانده شده به جدول فعلی اضافه می شوند. فرمت فایل متنی باید به گونه ای باشد که نام پارامترها در ستون اول و مقادیر هر پارامتر به صورت ردیفی با فاصله ای که نام و مقادیر را از هم جدا می کند و فاصله ای که مقادیر را از هم جدا می کند ظاهر شود.
روی دکمه Save to File ( ) کلیک کنید تا محتویات جدول در یک فایل متنی ذخیره شود (یا در صفحه گسترده Microsoft Excel Workbook اگر مجوز شامل LiveLink™ for Excel ® باشد ).
تا محتویات جدول در یک فایل متنی ذخیره شود (یا در صفحه گسترده Microsoft Excel Workbook اگر مجوز شامل LiveLink™ for Excel ® باشد ).
|
|
بارگیری و ذخیره داده های جدول پارامترها با استفاده از اکسل شامل واحدهای ستون واحد پارامتر می شود . هنگام ذخیره و بارگیری داده های پارامتر در فایل های *.txt، *.csv، و *.dat، ستون واحد نادیده گرفته می شود.
|
برای مطالعه Stationary یا Frequency Domain، گزینه ای را از لیست Run continuation for انتخاب کنید : بدون پارامتر یا یکی از پارامترهای ارائه شده در لیست.
|
|
|
راه حل استفاده مجدد از لیست مرحله قبلی
این گزینه برای پارامترهایی که با Continu کار نمی شوند مفید است. گزینه ای را از راه حل استفاده مجدد از لیست مرحله قبلی انتخاب کنید .
|
•
|
خیر (پیشفرض برای یک مطالعه ثابت) برای بازنشانی راهحل به مقادیر اولیه قبل از هر مرحله یا جابجایی ادامه. مقادیر اولیه توسط حل کننده پارامتری برای مقادیر پارامتر بعدی مجدداً محاسبه نخواهد شد. وابستگی پارامترهای مقادیر اولیه را می توان با استفاده از Sweep پارامتریک انجام داد.
|
|
•
|
بله برای اینکه همیشه از راه حل همگرای مرحله قبل یا آخرین راه حل از جابجایی ادامه قبلی استفاده کنید (یعنی هرگز راه حل را تنظیم مجدد نکنید).
|
|
•
|
خودکار (پیشفرض برای مطالعه دامنه فرکانس) برای استفاده معمولی از راهحل همگرا از مرحله قبل یا جارو کردن. با این حال، هنگامی که چندین پارامتر استفاده می شود، راه حل اولین مرحله از هر لیست پارامتر همیشه برای اولین مرحله از لیست بعدی استفاده می شود.
|
تفاوت بین سه گزینه در شکل 20-2 برای یک جارو دو پارامتری 3 در 4 با استفاده از گزینه های مختلف برای راه حل استفاده مجدد از مرحله قبل بدون ادامه نشان داده شده است: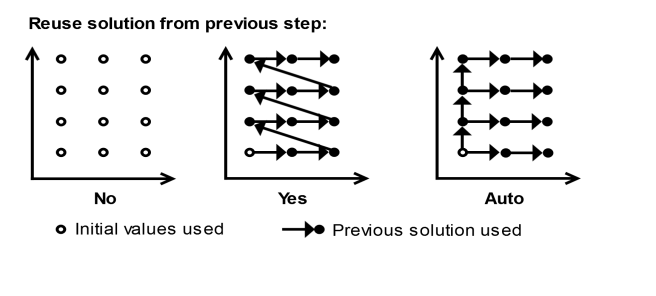
شکل 20-2: تفاوت بین سه گزینه برای جارو دو پارامتری بدون ادامه.
هنگامی که Continuation با تنظیم Run Continuation برای یکی از پارامترها فعال می شود ، راه حل های همگرا همیشه برای مراحل در امتداد جابجایی ادامه در این پارامتر دوباره استفاده می شوند. تنظیم راه حل استفاده مجدد از مرحله قبل، سپس تعیین می کند که چگونه راه حل ها بین چند جاروی ادامه دار استفاده مجدد شوند، اگر پارامترهای اضافی برای جارو کردن وجود داشته باشد، همانطور که در شکل 20-3 نشان داده شده است .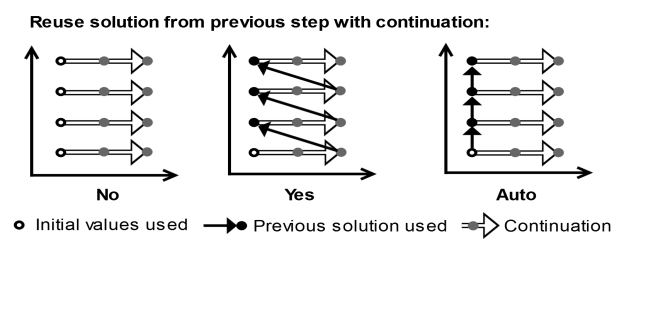
شکل 20-3: تفاوت بین سه گزینه برای جارو دو پارامتری با ادامه.
برای مطالعه دامنه فرکانس ، جارو کمکی با جابجایی فرکانس در یک جارو چند پارامتری با فرکانس به عنوان پارامتر در درونیترین سطح ادغام میشود.
برای اطلاعات بیشتر درباره حل پارامتری مراجعه کنید .



