
سوپر کامپیوتر
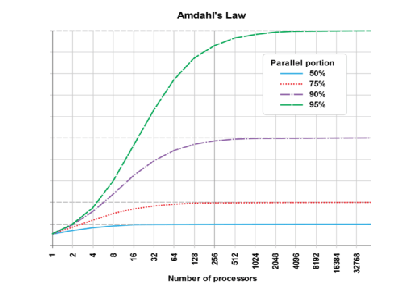
ابررایانههایی که پردازندههای سفارشی داشتند قبلاً سرعتی که روی کامپیوترهای معمولی داشتند را از طراحیهای ابتکاری شان به دست میآوردند که اجازه میداد مثل یک مهندسی به هم پیچیده چند کار را به صورت موازی انجام دهند. آنها را تنها برای انواع مشخصی از محاسبات مثل محاسبات عددی استفاده میکردند و در محاسبات کلی تر کامپیوتری ضعیف عمل میکردند. سلسله مراتب حافظهٔ آنها به دقت طراحی میشد تا دائماً اطلاعات و دستورالعمل در دسترس پردازنده قرار گیرد. در اصل عمدهترین تفاوت بین ابررایانههاو کامپیوترهای کندتر در سلسله مراتب حافظهشان است. سیستم ورودی/خروجی آنها برای پهنای باندهای بالا با تأخیر بسیار پایین طراحی شدهاست چرا که اساساً ابرکامپیوترها برای پردازش انتقالات طراحی نشدهاند. در اینجا هم مثل هر سیستم موازی قانون آمدال صدق میکند. طراحیهای مختلف ابررایانهها برای حذف تتابع (serialization) نرمافزارها تلاش بسیاری میکنند و برای رفع مشکلات و تنگناهای باقیمانده و تسریع آنها از سختافزار استفاده میکنند.
تکنولوژیها و دشواریهای سوپر کامپیوتر ها
یک کلاستر بیوولف
- یک ابررایانه گرمای زیادی تولید میکند و باید خنک شود. خنک کردن بسیاری ابررایانهها مسئلهٔ بسیار بزرگی برای HVAC است.
- اطلاعات نمیتوانند با سرعتی بالاتر از سرعت نور بین دو بخش کامپیوتر جابجا شوند. به همین دلیل یک ابررایانه چندمتری (با عرض چندمتر) باید تأخیر بین قطعاتش در حد چند ده نانوثانیه باشد. به خاطر همین مشکل طراحیهای سیمور کری کوشیدند در حد امکان از طول کابلهای کمتر استفاده کنند شکل استوانهٔ کری هم به همین ترتیب به وجود آمد. در ابررایانههایی که تعداد بسیار زیادی cpu دارند که موازی هم کار میکنند برای فرستادن پیام بین پردازندهها توقف یک تا پنج میکرو ثانیه معمول است.
- برای فرستادن پیام بین پردازندههاها حجم بسیار بالای اطلاعات را در مدت زمان کوتاه مصرف و تولید میکنند. کن بچر میگوید: برای فرستادن پیام بین پردازندهها وسیلهای است که مسائل محدود به محاسبه را محدود به I/O میکند. برای حصول اطمینان از انتقال سریع و ذخیرهٔ و بازیابی صحیح اطلاعات باید روی پهنای باند ذخیرهٔ خارجی کار زیادی انجام بدهیم.
تکنولوژیهای تولید شده برای ابررایانهها شامل اینها میشوند:
- پردازش برداری
- خنککنندگی مایع
- دسترسی ناهمشکل به حافظه (NUMA)
- دیسکهای راه راه (اولین نمونه از آنچه بعدها نامش RAID شد)
- فایل سیستمهای موازی
تکنیکهای پردازش
تکنیکهای پردازش برداری اوائل برای ابررایانهها طراحی و ایجاد شدهاند و برای کاربردهای سطح بالا و تخصصی استفاده میشوند. این تکنیکها به وفور وارد بازار معماری DSP و راهکارهای پردازش SIMD کامپیوترهای همه منظوره هم شدهاند. خصوصاً کنسولهای جدید بازیهای کامپیوتری از SIMD خیلی استفاده میکنند و به این دلیل است که برخی تولیدکنندگان ادعا میکنند ماشینهای بازی شان ابررایانه هستند. واقعیت این است که برخی کارتهای گرافیک توان محاسبهٔ چندین ترافلاپ (teraFLOP) را دارند. اولین پردازشهای کامپیوتری طبیعتی داشت که هدف خاصی را دنبال میکرد و کاربردهایی که میتوان برای این قدرت داشت را محدود میکرد با پیش رفته تر شدن بازیهای کامپیوتری واحدهای پردازش گرافیکی (GPUها) متحول شدهاست به عنوان پردازندههای برداری همه منظوره مفیدتر شدهاند و یک دیسیپلین کامل علوم کامپیوتری به وجود آمد تا از این توانایی استفاده کند به نام محاسبههای همه منظوره بر واحدهای پردازش گرافیکی(GPGPU).
سیستمعامل
سیستمعامل ابررایانهها که اغلب امروزه انواعی از لینوکس و یونیکس هستند و اگر پیچیدهتر از ماشینهای کوچکتر نباشند همان قدر پیچیده هستند. ظاهری که کاربر میبیند سادهتر است چون سازندگان OSها منابع برنامهنویسی کمتری برای سرمایهگذاری بر بخشهای غیرضروری OSها (یعنی بخشهایی که مستقیماً به بهترین کاربرد سختافزار نمیشود) دارند. دلیل اصلی آن این است که این کامپیوترها میلیونها دلار قیمت دارند امابازار خریدشان بسیار کوچک است لذا بودجههای R&D شان اغلب محدود است. وجود یونیکس و لینوکس اجازه میدهد ظاهر کاربری (user interface) نرمافزار دسکتاپ معمولی دوباره مورد استفاده قرار بگیرد. جالب آنجا ست که در تاریخ صنعت ابررایانهها این روند هم چنان ادامه پیدا کردهاست و رهبران قدیمی این تکنولوژی از جمله Silicon Graphics در برابر امثال nVIDIA عقب نشستهاند چرا که اینها میتوانند محصولات ابتکاری ارزان و پرفایده و پرکاربرد را به لطف مشتریان بسیارشان که R&D آنها را تأمین میکنند تولید نمایند. از نظر تاریخی تا ابتدا و میانهٔ دههٔ ابررایانهها اغلب سازگاری گروه دستورات و قابلیت جابجایی کدها را فدای عملکرد و سرعت پردازش و دسترسی به حافظهٔ کامپیوتر میکردند. اغلب ابررایانهها تا به امروز برخلاف کامپیوترهای گرانقیمت فنی high end main frames سیستمهای عامل بسیار متفاوتی دارند. Cray-۱ به تنهایی شش OS مخصوص خودش را داشت که جامعهٔ کامپیوتر هیچ خبری از آنها نداشت. مشابه آن کامپایلرهای برداریکننده و مواز یکنندهٔ بسیاری هم برای فرترن موجود بود. اگر به خاطر سازگاری گروه دستورات اولیه بین Cray-۱ و Cray x-mp و پذیرش انواع OSهای یونیکس مثل CrayUnicos و لینوکس نبود این اتفاق برای ETA-۱۰ هم میافتاد. به همین دلیل در آینده سیستمهایی با بالاترین کاربرد احتمالاً رنگ و بویی از یونیکس خواهند داشت اما با خاصیتهای مخصوص سیستم ناسازگار خصوصاً برای سیستمهای بسیار فنی و گرانقیمت با امکانات امن مطمئن.
برنامهنویسی
معماری موازی ابررایانهها ایجاب میکند تکنیکهای برنامهنویسی خاصی برای سرعت بالایشان استفاده شود. کامپایلرهای هدفمند فرترن معمولاً میتوانند کدهای سریع تری از C یا C++ تولید کنند. به این دلیل فراترن همچنان بهترین انتخاب برای برنامهنویسی علمی و البته برای اکثر برنامههایی که روی ابررایانهها اجرا میشود باقی میماند. برای بهرهوری از موازی بودن ابررایانهها، محیطهای برنامهنویسی خاصی برای برنامهنویسی آنها استفاده میشود از جمله برای بستههای کامپیوتری پراکنده و دور از هم PVM و MPI و برای ماشینهای حافظه اشتراکی بسیار نزدیک به هم OpenMP استفاده میشود.
معماری ابررایانه مدرن
چنانکه در فهرست نوامبر ۲۰۰۶ میبینیم ده کامپیوتر برتر فهرست پانصد کامپیوتر برتر (و البته بسیاری کامپیوتر دیگر در این لیست) معماری سطح بالا اما مشابهی دارند. هر کدام مجموعهای از مولتی پروسسورهای تماماً SIMD هستند. هر ابررایانهای بسته به تعداد مولتی پروسسورهای مجموعه، تعداد پروسسورهای هر مولتی پروسسور و نیز تعداد عملیاتی که میتواند به صورت همزمان در هر پروسسور SIMD انجام بدهد از سایر ابررایانهها متفاوت میشود. در این سلسله چنین چیزهایی داریم:
- یک مجموعه کامپیوتری که کامپیوترهای آن از طریق شبکهٔ سرعت بالا یا شبکهٔ تعویض (switching fabric) اتصال بسیار مفصلی با هم دارند. هر کامپیوتر هم تحت نمونهٔ مجزایی از OS کار میکند.
- کامپیوتر مولتی پروسسور کامپیوتری است که تحت OS مشخصی کار میکند و بیش از یک CPU دارد و در آن نرمافزار سطح عملکرد از تعداد پروسسورها مستقل است. وظایفی مثل مولتی پروسسینگ متقارن (SMP) و دسترسی غیرهمشکل به حافظه (NUMA) را با هم انجام میدهند.
- یک پروسسور SIMD یک دستور را بر چندین دسته اطلاعات به صورت همزمان اجرا میکند. پردازنده میتواند چندمنظوره یا برداری با کاربرد خاص باشد. سطح عملکرد هم میتواند بالا یا پایین باشد.
طبق بررسی ماه نوامبر سال ۲۰۰۶ قانون مور (Moore) و اقتصاد مقیاسی (economy of scale) فاکتور اصلی در طراحی ابررایانهها هستند. یک PC دسکتاپ مدرن امروزه قوی تر از یک ابررایانه پانزده سال پیش است و این طراحیهایی که سابقاً اجازه میداد ابررایانهها از ماشینهای دسکتاپ بهتر عمل کنند در طراحی PCها استفاده میشوند. به علاوه هزینههای ایجاد تراشهها (چیپchip) باعث میشود طراحی تراشههای سفارشی برای کاربرد محدود مقرون به صرفه نباشد بلکه تولید انبوه تراشهها را تأیید میکند که مشتری داشته باشند و هزینهٔ تولید را پوشش بدهد. یک واحد کاری مدل هسته چهارگانه Xeon با عملکرد GHz۲٫۶۶ از یک ابررایانه C۹۰ کری چند میلیون دلاری که در دههٔ ۱۹۹۰ استفاده میشد بهتر است و حجم بسیار بالایی از کار که در دههٔ ۱۹۹۰ به چنین ابررایانهای نیاز داشت امروزه با یک واحد کاری کمتر از ۴۰۰۰ دلاری انجام میشود. مسایلی که ابررایانهها آنها را حل میکردند اکثراً باید موازیسازی میشدند (یعنی تقسیم کار بزرگ به چند کار کوچکتر برای انجام همزمان) آن هم به قطعات بزرگ تا حجم اطلاعاتی که بین واحدهای پردازندهٔ مستقل انتقال پیدا میکرد کاهش پیدا کند. این است که میتوان به جای بسیاری ابررایانههای سنتی از بستههای طراحی استاندارد بهره برد که با برنامهریزی قابلیت عملکرد یگانه و همگرا را دارند.
← مرکز محاسبات سریع شبیهسازان امیرکبیر →
ابررایانههای هدفمند و دارای کاربرد خاص
ابررایانه بلو جین، محصول آی بی ام در آزمایشگاه ملی آرگون
ابررایانه هدفمند ابزارهای محاسباتی با عملکرد بسیار سطح بالا و معماری سختافزاری مناسب حل یک مسئلهٔ خاص هستند. میتوان در آنها از تراشههای FPGA برنامهریزی شده یا چیپهای VLSI سفارشی استفاده نمود که عمومیت شان را از دست میدهند اما در عوض نسبت قیمت به کاربرد بالاتری ارائه میدهند. از آنها برای محاسبات نجومی و کد شکنیهای بسیار قوی استفاده میشود. پیش آمدهاست که یک ابررایانه هدفمند جدید از برخی نظرها از سریعترین ابررایانه وقت سریع تر عمل کند مثلاً GRAPE-۶ که در سال ۲۰۰۲ در برخی مسائل سریع تر از شبیهساز زمین عمل کرد. مثالهایی از ابررایانه هدفمند
- DEEP BLUE برای بازی شطرنج
- ماشینها یا ابزار و قطعات ماشینهای محاسبهٔ قابل پیکربندی مجدد
- GRAPE برای فیزیک نجوم و دینامیک مولکول
- DEEP CRACK برای رمزشکنی DES
سریعترین ابررایانه روز
محاسبهٔ سرعت ابررایانه
سرعت ابررایانه بر اساس FLOPS محاسبه میشود که مخفف عملیات دقیق شناور در هر لحظه میباشد و معمولاً هم یک پسوند SI مثل ترا یا پتا با آن است. در حالت ترا بودن آن را TFLOPS ترافلاپ ده به توان دوازده FLOP و در حالت پتا بودن PFLOPS پتافلاپ ده به توان پانزده میگویند. این محاسبهٔ بر اساس مقیاسی که مارتیس بزرگ را تجزیه ی(LU decomposition میکند صورت میگیرد. این نمونه مسائل حقیقی را بررسی میکند اما خیلی راحتتر از محاسبهٔ مسائل دنیای واقعی است.
فهرست پانصد عنوان برتر
از سال ۱۹۹۳ نتایج LINPAK پانصد ابررایانه سریع دنیا را همواره رتبهبندی نمودهاست. البته ادعا نمیشود این فهرست کاملاً بی ایراد است اما بهترین از سرعت کامپیوتر را در هر زمان دارد.
سریعترین ابررایانه فعلی
پس از Tianhe-1A، نوبت به این غول چینی رسید تا رکورد سرعت را با ثبت عدد ۳۳٫۸۶ پتافلاپس بشکند. Tianhe-2 از پردازندههای Xeons و Xeon Phi اینتل از سری آیوی بریج استفاده میکند و در مجموع ۳ میلیون و ۱۲۰ هزار هسته پردازشی دارد. این ابر کامپیوتر که ۱۷٬۸۰۸ کیلووات مصرف انرژی دارد، بر روی کاغذ قادر است به سرعت ۵۴٫۹ پتافلاپس هم دست یابد. پس اگر لازم شد، شاید بتواند برای حفظ جایگاه خود، سرسختانه بجنگد. منبع
ابر شبه محاسبه (کازی سوپر کامپیوتینگ quasi super computing)
برخی انواع محاسبات توزیع شدهٔ مقیاس وسیع برای مسائل بسیار موازیسازی شده را میتوان اوج ابر محاسبهٔ دستهبندی شده نامید. مثلاً پلتفرم BOINC (که میزبان تعدادی پروژهٔ محاسبهٔ توزیع شده هستند) در بیست و هفتم مارس سال ۲۰۰۷ از طریق ۱۷۹۷۰۰۰ کامپیوتر اضافه روی شبکه بالای ۵۳۰٫۷ ترافلاپ سرعت عملکرد به ثبت رساند. سریعترین پروژه بود SETI@home که با ۱۳۹۰۰۰۰ کامپیوتر اضافه ۲۷۶٫۳ ترافلاپ کار میکرد. یک پروژهٔ توزیع شدهٔ دیگر Folding@home بود که در اواخر سپتامبر ۲۰۰۷ قدرت عملکرد برابر ۱٫۳ پتافلاپ گزارش داد. مشتریانی که از پلی استیشن استفاده میکنند از توان محاسبهٔ بالا ۱ پتافلاپ استفاده میکنند. تحقیق Mersenne Prime توزیع شدهٔ GIMP تا اکتبر ۲۰۰۷ قدرت برابر ۲۳ ترافلاپ به ثبت رساندهاند. سیستم موتور جستجوی گوگل با ۱۲۶ تا ۳۱۶ ترافلاپ احتمالاً سریعترین باشد.
تحقیق و توسعه
در نهم سپتامبر سال ۲۰۰۶ دفتر مدیریت امنیت هستهای ملی انرژی آمریکا (NNSA)، آی بی ام(IBM) را برای طراحی و ساخت اولین ابررایانه دنیا انتخاب کرد. سیستمی که برای تولید ماشینی پردازندهٔ موتور پنهای باند سلولی (cell BE) ماشینی با توان پایستهٔ یک پتافلاپ یا یک هزار تریلیون محاسبه در ثانیه بسازد. پروژهٔ دیگری که IBM به آن مشغول است ساخت Cyclops۶۴ است که قرار است روی یک تراشه یک ابررایانه نصب کند. دکتر کارمارکار در هند پروژهای را برای ساخت ابررایانه یک پتافلاپی رهبری میکند. CDAC هم در حال ساخت رهبری میکندی است که تا سال ۲۰۱۰ بتواند به یک پتافلاپ برسد. NSF هم پروژهای بیست میلیون دلاری برای ساخت یک ابررایانه یک پتافلاپی در دست دارد. NCSA هم در دانشگاه ایلینوی اوربانا شامپاین مشغول چنین پروژهای است و برآورد میشود تا سال ۲۰۱۱ آن را تکمیل کند.
جدول زمانی ابررایانهها
اینجا جدولی از سریعترین ابررایانههای رکورددار همه منظورهٔ موجود در دنیا با سال کسب رکوردشان را میبینید. منبع عناوینی که سال ثبتشان قبل از سال ۱۹۹۳ است مختلف است اما برای عناوین بعد از سال ۱۹۹۳ از فهرست پانصد کامپیوتر برتر دنیا استفاده کردهایم.
منبع : ویکی پدیا



دیدگاهتان را بنویسید